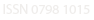
 HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN
HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN Espacios. Vol. 37 (Nº 12) Año 2016. Pág. 10
Emerson RABELO 1; Fernando Celso CAMPOS 2
Recibido: 04/01/16 • Aprobado: 02/03/2016
3. Descoberta de conhecimento em banco de dados (KDD)
RESUMO: O cenário organizacional vem sofrendo muitas alterações nas últimas décadas. Um exemplo destas modificacões esta na evolução tecnológica, isto é, na capacidade de armazenamento e processamento de um grande volume de dados. Com esta explosão tecnológica surgem novos desafios. O presente artigo Realiza uma análise Bibliométrica dos artigos publicados no período de 2009 a 2014, que tem a preocupação da utilização e efetivação da descoberta de conhecimento na gestão do conhecimento. A metodologia utilizada consiste em uma análise Bibliométrica, para obter informações do andamento e comportamento das publicações científicas, que relacionam temas relevantes na descoberta de conhecimento para identificar possíveis lacunas. |
ABSTRACT: The organizational setting has undergone many changes in recent decades. An example of these modifications on this technological evolution, this is, in the storage and processing of a large volume of data. With this technological explosion new challenges. This article performs a Bibliometric analysis of articles published from 2009 to 2014, which is concerned the use and effectiveness of knowledge discovery in knowledge management. The methodology consists of a Bibliometric analysis, for information on the progress and behavior of scientific publications that relate relevant issues in the discovery of knowledge to identify possible gaps. |
O mundo corporativo e a sociedade esta presenciando um cenário raro de complexidade. Este fenômeno tanto econômico como social são responsáveis pela reestruturação do ambiente de negócios. Atualmente a competitividade e a velocidade dos processos no mundo empresarial exigem que as tomadas de decisões e desenvolvimento de estratégias, sejam realizadas com base em conhecimentos úteis e concretos. Oferecer oportunidades dos gestores obterem visões de diferentes dimensões da dinâmica da sua empresa pode criar um diferencial significativo. Por exemplo: atualmente alguns consumidores comentam em redes sociais informações sobre o produto adquirido de uma determinada empresa, sendo que, geralmente o departamento de marketing desta organização tem apenas as informações transacionais que estão armazenadas em seu banco de dados, no entanto, existem informações potenciais de consumidores que dizem o que pensa sobre o produto. Consegui mensurar as atividades da relação da empresa com os clientes de diferentes dimensões pode abrir oportunidades sem precedentes.
Gestão do conhecimento (GC) tem a preocupação de captar, gerar, criar, analisar, traduzir, transformar, modelar, armazenar, disseminar, implantar e gerenciar a informação, tanto interna como externa. Nos quesitos analisar e traduzir existem grandes área de pesquisa denominada KDD (Knowledge Discovery in Databases), esta área foi realmente formalizada em 1989 com interesse de conceituar a busca por conhecimento a partir de banco de dados. Esta área é dividida em três etapas: Pré-processamento que na GC pode ser utilizada para captar, gera e criar. Mineração de dados que na GC é a fase de analisar e no pós-processamento que é a tradução dos resultados alcançados. Sendo assim, é possível visualizar a inserção da área de descoberta de conhecimento na gestão do conhecimento, pensado desta forma, o presente artigo tem como objetivo gerar uma analise bibliométrica dos principais artigos no período de 2009 a 2014 para relacionar os temas que norteam a descoberta de conhecimento na gestão de conhecimento.
Considerado como um processo que envolve a geração, coleta, assimilação e aproveitamento do conhecimento, para a criação de estratégica de negocio e aumentar a inteligência competitiva. Murray (1996) define como uma estratégia que tem a capacidade de transformar os bens intelectuais da organização, informações registradas e o talento dos seus membros, em maior produtividade, novos valores e aumento de competitividade. Na gestão do conhecimento o cerne é o conhecimento. No dicionário Aurélio a teoria do conhecimento é definida como estudo da origem e do valor do conhecimento em que se focaliza, especialmente, a relação entre o sujeito e o objeto e, nessa relação, o modo e os graus de atividade ou passividade de cada um deles. Isto é, o conhecimento é ato ou efeito de abstrair idéia ou noção de um objeto por meio de acúmulo de experiências e práticas.
A aceitação da implantação da Gestão do Conhecimento (GC) cria uma vantagem competitiva sustentável, pois as pessoas são responsáveis, isto é, está enraizada nelas que trabalham na empresa, e não em recursos físicos, que são facilmente imitáveis pelos concorrentes (QUINN et al., 1997). Importante complementar que as pessoas envolvidas nos processos podem ser as mesmas responsáveis no desenvolvimento tecnológico para a criação de soluções na captura, extração e interpretação de conhecimentos, tarefas pela qual o humano estaria limitado.
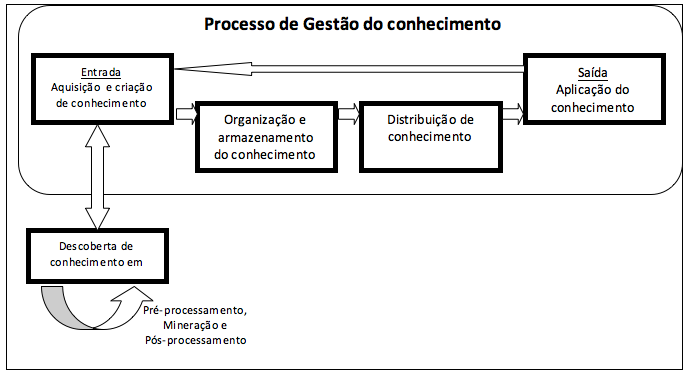
Figura 1 – Processo de gestão do conhecimento – Fonte: Adaptado – (BARTHÈS, 1998)
Atualmente o aumento no volume de dados analisados ultrapassou a barreira dos processos internos transacionais das empresas, o interesse também esta nos dados advindos das atividades online (redes sociais), telecomunicação (tecnologia móvel) e cientificas (simuladores, sensores e experimentos). Neste contexto O KDD se torna uma importante área estratégica no mundo dos negócios, governo, organizações e instituições de pesquisas, no entanto é necessário que a organização aplique práticas tecnológicas para o gerenciamento e analise dos dados (BEGOLI e HOREY, 2012).
KDD foi formalizado em 1989 para atender os processos referentes à busca de conhecimento a partir de bases de dados. Uma das definições mais populares foi proposta em 1996 por um grupo de pesquisadores (FAYYAD et al., 1996, p. 30):
"KDD é um processo, de várias etapas, não trivial, interativo e iterativo, para identificação de padrões compreensíveis, válidos, novos e potencialmente úteis a partir de grandes conjuntos de dados"
Interativo indica a atuação do Homem para a realização dos processos, sendo ele o responsável por utilizar as ferramentas computacionais para análise e interpretação dos dados. Para obter um resultado satisfatório, é necessário muitas vezes repetir o processo de forma integral ou parcial, ou seja, o processo é iterativo, porém, o fato do processo ser repetitivo não o torna automático, pois exige a necessidade da interferência humana que engloba a psicologia cognitiva e sistemas de memorização, analise e aprendizado. Para Murray et al. (2005) é importante ter uma abordagem visual onde o humano acompanha todo o processo com a utilização de gráficos, este complemento facilitará a intervenção humana durante a analise. A descoberta de conhecimento em base de dados é o processo de extração de conhecimento por meio da manipulação de dados. Feldens et al. (1998) define as seguintes etapas para KDD:
Conforme definido por Fayyad (1996) que o KDD tem várias etapas que não são triviais e Feldens (1998) definiu estas etapas que são iterativos e interativos para identificação de padrões. Neste caso é interessante ressaltar que cada etapa tem suas particularidades e complexidades que envolvem ferramentas tecnológicas, a Figura 2 apresentada no artigo dos autores Begoli e Horey (2012) ilustra bem a interdisciplinaridade existente no processo KDD (ciência da computação, estatísticas, visualização e o domínio da área ) e as etapas de pré-processamento (dados), mineração de dados (ferramentas de análise) e pós-processamento (entendimento do domínio).
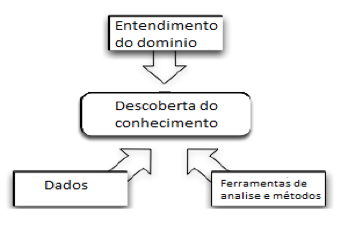
Figura 2 – Elementos do processo de descoberta de conhecimento
(BEGOLI e HOREY, 2012).
Conforme já citado a mineração de dados pode ser considerada como uma parte do processo de KDD. Goldschmidt e Passos (2005) afirmam que esta é a principal etapa. Segundo Shimabukuru (2004), estima-se que a MD represente de 15% a 25% do processo de KDD. Nessa etapa que compreende a aplicação de algoritmo para extrair e ser capaz de identificar padrões, estruturas, tendências e revelar novidades que sejam úteis e de interesse do usuário, vários métodos podem ser usados em função da natureza dos dados e das informações que se desejam alcançar.
Mineração de dados também pode ser definida como a descoberta de informações úteis a partir de um conjunto de dados. Para a obtenção dessas informações, é necessária a utilização de técnicas e tarefas de busca por relacionamentos e padrões existentes entre os dados (DIAS, 2001).
A presença humana na escolha e combinação das opções de cada etapa do processo KDD é essencial devido, principalmente, a sua intuição, e experiência anterior e conhecimentos para analisar, interpretar, direcionar e combinar estratégias a serem realizadas. Fayyad, Piatestky e Smyth (1996) e Goldschmidt e Passos (2005) consideram o especialista no domínio de aplicação como um dos principais componentes necessários para melhor compreensão do processo KDD. Goebel e Gruenwald (1999) relacionam fatores humanos necessários a cada etapa do processo KDD. Eles são classificados como: especialista em mineração de dados, em KDD, no domínio da aplicação e usuários finais (engenheiros, gerentes, administradores, etc.). Obviamente a existência de profissionais diferentes nestes estágios exige demandas diferentes e trazem pré-requisitos diferentes. Geralmente, os usuários finais não têm capacidade de efetuar uma análise complexa nos dados, mas natural mente eles têm um grande conhecimento do domínio da aplicação. De forma geral, é o ser humano que executa a difícil tarefa de orientar e executar o processo KDD, conforme ilustrado na Figura 3.
Figura 3 - Ser humano como elemento central do processo de KDD.
Fonte: Adaptado de (GOLDSCHMIDT; PASSOS, 2005, p. 22).
Goldschmidt e Passos (2005) apresentam o especialista em KDD como pessoa ou grupo de pessoas experientes para direcionar a execução do processo, que define o que, como e quando deve ser realizada cada ação. O especialista em KDD interage com o especialista no domínio de aplicação. Mesmo que o processo KDD seja automatizado, o fator humano é essencial para o sucesso de sua realização, porque é ele que tem a compreensão do domínio dos dados (natureza, forma econteúdo), sendo pré-requisito indispensável na abstração de qualquer conhecimento útil. Na etapa de pré-processamento, por exemplo, é necessário o conhecimento sobre o domínioda aplicação e domínio de dados para facilitar a organização, limpeza e seleção do conjunto de dados.
As definições existentes na literatura para Big Data convergem para os seguintes fatos, a utilização de diferentes fontes, tipo de dados e características que se refere ao volume, variedade e velocidade (MANYIKA et al.,2011; IBM, 2011; BEGOLI e HOREY, 2012; MCFEE e BRYNJOLFSSON, 2012) outros autores como o Zikopoulos (2011) acrescenta o atributo veracidade. A menos de 10 anos atrás, usava-se muito o termo Giga-Bytes e rapidamente mudou-se paraTerabytes e atualmente se fala em Petabytes e exabyte, desta forma é possível observar como o volume de dados no mundo cresce rapidamente.
Os autores Mcafee e Brynjolfsson (2012) fez uma estimativa que a cada dia ocorre um aumento de 2.5 exabytes de produção de dados, e aproximadamente daqui 4 anos este número irá dobrar. De acordo com a pesquisa realizada por Gantz e Reinsel (2012) a previsão é que em 2020 será produzido mais de 40.000 exabyte (mais de 5.200 gigabytes para cada habitante no mundo). Espera-se que nesta mesma proporção a evolução tecnológica possa acompanhar o processamento, organização e gerenciamento do alto volume de dados e o Big Data faz parte desta evolução. O fator variedade refere-se aos dados de tipos e fontes distintas tais como, sensores, navegadores, áudio, arquivos textos, centrais de sistemas embarcados, vídeos, fotos e etc... A característica velocidade se refere à preocupação com a latência na busca e processamento dos dados, pois existem alguns conhecimentos descobertos que podem perder sua utilidade pelo fator tempo. Se o conhecimento for oferecido em tempo real e a organização conseguir utilizá-la de forma eficaz, isto lhe dará uma vantagem competitiva. O aspecto veracidade citado pelo pesquisador o Zikopoulos (2011) relaciona-se a questão da qualidade dos dados, pois dados com problemas podem gerar conhecimentos falhos, desta forma é importante considerar os fatores que classificam ou tornam os dados com qualidade.
De acordo com a definição acima sobre as características que compõem o Big Data, é fácil identificar que este campo é muito fértil e possibilitam novas idéias, invenções e pesquisas, o desafio de encontrar conhecimentos valiosos tais como perfil do cliente, hábitos, satisfação e gostos, tem-se uma complexidade no que tange aos dados não estruturados, isto é, dados que podem não estar em Banco de Dados tradicionais e além deste fato, existe a volatilidade que é característica que pode dificultar a análise, pois os dados sofrem modificações constantes.
São inúmeras as possibilidades da aplicação do Big Data, os autores McAfee e Brynjolfsson (2012) realizaram uma pesquisa sobre as vantagens das empresas que utilizam o Big Data, e concluíram que as que fazem uso têm um aumento de 6 % em seus lucros e 5% a mais na produtividade. No Brasil existem alguns estudos, a pesquisadora Breitman (2012) afirma que "A descoberta do pré-sal só foi possível por causa do Big Data", neste caso se trata de dados sísmicos advindos de sondas que estão no fundo do mar, que gera um alto volume de dados de entradas de diferentes variáveis, que são filtradas e processadas para conhecimentos confiáveis da superfície avaliada, o Big Data neste contexto atende as necessidades de captar, processar, gerenciar, visualizar e processar os dados. Outro artigo publicado recentemente por Correa (2013) afirma que o "Uso de Big Data ajuda o governo brasileiro a gastar de forma mais eficiente", esta afirmação é referente a um projeto de inovação da FGV que utiliza o Big Data para análise econômica, utiliza como fontes de dados o portal do "ComprasNet" que um sistema virtual de aquisição de bens e serviços para o setor público. Este projeto foi debatido no fórum da OCDE (Organização para Cooperação e Desenvolvimento Econômico) em Paris e pretende se estender a aos outros países interessados. A economia gerada na aplicação do sistema é em torno de R$866 milhões somente no período entre os anos de 2008 a 2010, fato que chama a atenção é que esta redução de gasto foi somente em um Ministério Brasileiro, somente no poder executivo existem 24 ministérios, imagine uma redução nesta proporção para cada ministério, o valor com certeza seria significativo. Exposto os fatos, é visível como o Big Data pode trazer altos benefícios em uma organização.
O objetivo dos estudos bibliométricos é conhecer como esta o andamento e comportamento das publicações científicas, com pretensão de saber quem são os autores que atuam em determinado assunto e os autores que são considerados como referencias na área, dentre muitas outras informações relevantes, diferentes comunidades cientificas tem o seu próprio método de oferecer e conhecer a sua produção, no entanto é importante identificar variáveis legitimas e adequadas para retratar a atividades coletiva do volume de pequisa de cada pais para isto existe a abordagem bibliométrica que apóia as tarefas de mensurar e também indicadores que possam demostrar a saturação ou lacunas existentes entre diversos temas (KOBASHI e SANTOS, 2008).
A primeira etapa foi o cuidado na escolha das bases de dados, é fato que nem todos os trabalhos científicos estão disponíveis de bases de patentes ou de publicação, existem muitos que nem são divulgadas por serem confidencial. Neste caso, foram selecionada base de dados relevantes sobre o tema em estudo para combinar a pesquisa. Importante ressaltar que as bases de dados da SCOPUS e WoS (Web of Sciences) geram similaridades em seus resultados com de alta correlação (ARCHAMBAULT et. Al. , 2009).
O objetivo maior deste trabalho é das publicações cientificam que abordam o tema da descoberta de conhecimento (DC) na gestão do conhecimento (GC) no perido de 2009 a 2014, as buscas foram feitas nos banco de dados dos seguintes periódicos:
No entanto os resultados das buscas com a utilização dos campos chaves "Gestão do conhecimento" e "Descoberta de conhecimento", no quesito quantitativo não foram tão expressivos, o retorno foram de 26 artigos e apenas o total de 11 artigos foram selecionados, pois atendem a proposta da avaliação deste trabalho. Sendo assim, a idéia foi aumentar o nivel de busca com intuito de encontrar pesquisas que trabalham com a relação entre a as duas áreas (GC e DC).
Como já visto acima, a etapa de mineração de dados (Data mining – DM), pertence à área de descoberta de conhecimento em banco de dados (KDD), no entanto existem muitas pesquisas em torno somente da etapa da mineração de dados, desta forma, os campos chaves foram alterados para Gestão do conhecimento e mineração de dados (DM). Os resultados foram de 50 artigos e apenas 28 foram selecionadas.
O número de pesquisas sobre mineração de dados (DM) e descoberta de conhecimento (DC) atinge as casa de milhares, no entanto se restringir a pesquisa para os campos chaves DM e DC com a preposição "AND", os resultados diminuem para 227 artigos, destes apenas 43 artigos foram selecionados. Atualmente surgiram pesquisas sobre "Big Data" e mesma pertence à área de descoberta de conhecimento, pensando desta forma, foram feitas buscas com os campos chaves Big Data (BD) e Gestão do conhecimento (GC), o resultado foram de 5 artigos e apenas 3 foram selecionados.
A Figura 4 demonstra os resultados das buscas no banco de dados dos periódicos e a os artigos selecionados, conforme pode ser observado à ordem decrescente do quantitativo de publicações dos temas, são: DC x DM, GC x DM, GC x DC e por fim GC e BD Figura 5. É possível afirmar que as pesquisas tem uma preocupação maior na etapa da mineração de dados, e não se atendam as etapas de pós-processamento e pré-processamento. Cada uma tem as suas peculiaridades e complexidades, porém tem em comum a sua importância na descoberta do conhecimento. Foram selecionados 85 artigos de um total de 308.

Figura 4 – Resultados e seleção dos campos chaves do banco de dados dos periódicos. Fonte: SCOPUS (2015).
----
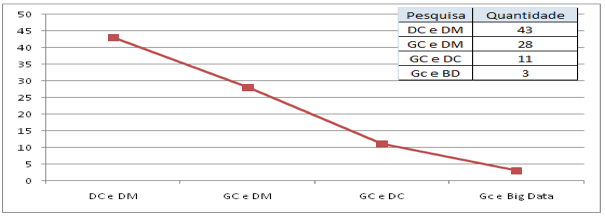
Figura 5 - Quantidade dos artigos selecionados de acordo com as relações dos temas. Fonte: SCOPUS (2015).
A Figura 6 apresenta uma tabela que demonstra os anos de publicação da quantidade de artigos com os temas relacionados, foi possível observar que os temas GC e DC, tem o quantitativo estável no decorrer dos anos, com intuito de confirmar esta afirmação, foram feitas as mesmas pesquisas na SCOPUS que por fim demonstraram os mesmos resultados.
A SCOPUS é um banco de dados de resumos e citações de artigos de jornais e revistas acadêmicos, este banco de dados é propriedade da Elsevier, sendo uma editora importante de revistas cientificas internacionais. Atualmente a Scopus conta com mais de 50 milhoes de registros, 5,5 milhões de documentos de conferências, 29 milhões de registros, incluindo referências, até 1995 (84% incluem resumos), 21 milhões de registros anteriores a 1996 que vão até 182 e etc... Com estes números é fato que se torna uma base de dados relevante para um trabalho com pretensões de analise bibliométrica.
Na Figura 7 é possível visualizar que dentre os artigos selecionados, aproximadamente 50% abordaram na pesquisa o uso de dados "estruturados" e "não estruturados", originados de Banco de Dados ou da internet (fórum, redes sociais e etc..), observa-se também que os artigos que utilizaram as fontes de dados retiradas da internet são de aproximadamente 20%. Isto significa que de todos os artigos que trabalharam com dados como protagonista, 40% Utilizou dados advindos da internet, que geralmente são dados não estruturados e que atualmente é aplicado na área do "Big Data".
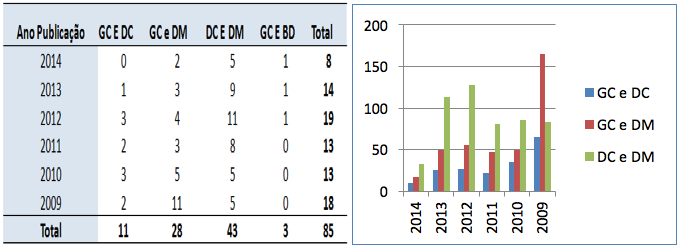
Figura 6 – Tabela e Gráfico dos anos de publicação da quantidade de artigos com a relação entre os temas
Fonte: SCOPUS (2015).
Ainda na Figura 7, constata-se outro fato relevante que é a falta de desenvolvimento de protótipos, aproximadamente 6% dos artigos selecionados, no entanto, o uso e métodos que apoiam o desenvolvimento de software esta na casa dos 23%, sabe-se que esta área necessita de testes e validações, e os protótipos são ferramentas adequadas para tal, desta forma, observa-se uma lacuna existente entre a teoria, prática e validação das descobertas. Esta afirmação atinge todas as pesquisas que necessitam de alto volume de dados e que diretamente implicam no alto processamento.
A área que envolve o "Big Data" compreende alguns estudos sobre a "semântica", e dentre os artigos selecionados, apenas 9% atendem este tema. Então, além de toda a complexidade na manipulação de dados "não estruturados" este tema ainda se encontra carente, dentre os trabalhos selecionados encontra-se o artigo intitulado "A keyword extraction method from twitter messages represented as graphs" dos autores Brasileiros, Abilho D. W. Castro L. N. Publicado em 2014 na revista Elsevier na área de computação e matemática. Este artigo se destaca nos estudos da extração das principais palavras por meio de grafos.
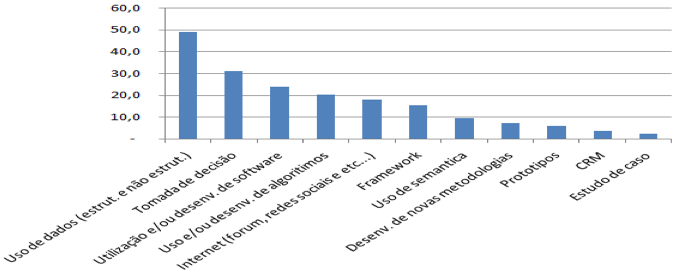
Figura 7 – Temas dos artigos selecionados
Fonte: SCOPUS (2015).
A Figura 8 apresenta os temas que se destacam, para as buscas que relacionam DC e DM, encontram-se com o maior quantitativo na base dados da SCOPUS as áreas de matemática e biológicas. Na relação entre as palavras chaves GC e DC os temas mais pesquisados estão na área social e medicina. Para os termos GC e DM esta a área social e ciência da computação. Sugere-se que o fato da computação ter um quantitativo maior, é que na mineração de dados exige o desenvolvimento de algoritmos computacionais.
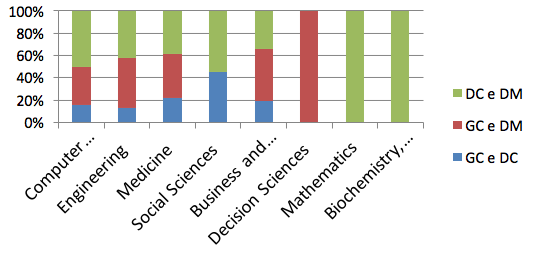
Figura 8 – Tema de estudo da base de dados SCOPUS
Fonte: SCOPUS (2015)
Dentre os autores pesquisados, temos o autor Ajith Abraham (Abraham A.), de Dalian Maritime University, School of Information Science and Technology, em Dalian na China, os trabalhos publicados estão na área de ciências sociais e ciência da computação, estes artigos podem auxiliar pesquisas nas áreas de gestão do conhecimento e inteligência competitiva. O autor Farhan Chowdhury Ahmed da University of Dhaka, Department of Computer Science and Engineering em Dhaka no Bangladesh, teve 192 citações em total de 35 artigos publicados com outros autores. Na Figura 8, este mesmo autor tem 9 publicações do tema de GC, DC e DM, no período de 2009 a 2014, as suas publicações tem sido fortemente na área de banco de dados, semáticas e indenficações de padrões.
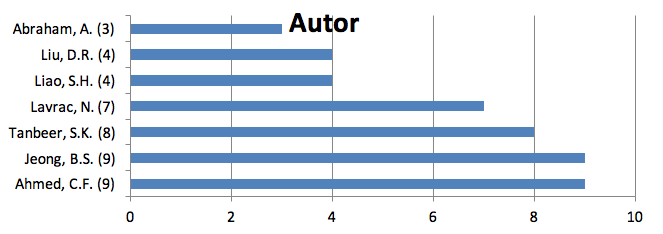
Figura 9 – Número de publicação dos temas GC, DC e DM por autores, fonte: Web of Science (2015)
É possível observar no gráfico da Figura 10 que a produção que envolve a relação entre os temas estão na mesma proporção em todos os Países, com exceção da Espanha. Outro ponto observado é o numero de publicações dos Estados unidos e da China.
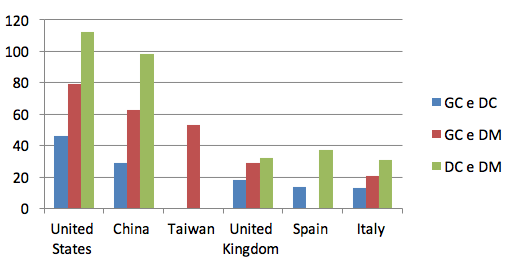
Figura 10 – Número de publicação por Países - GC, DC e DM, fonte: Web of Science (2015)
Os recentes artigos tratam o Big Data como uma revolução, no entanto existem poucas menções sobre Data Mining, mesmo existindo uma correlação entre ambos, historicamente a estatística e o Data Mining foram os precussores para o surgimento do Big Data, e não existe muita menção sobre tal fato. Os primeiros artigos que abordam o tema Big Data na base de dados da SCOPUS foram no ano de 2011, já os artigos que contemplam a área de Data Mining teve inicio em 1985 com um aumento significativo a partir do ano de 2000. A figura 11a, apresenta a evolução no numero de artigos durante o período de 1994 a 2014. A Figura 11b, demonstra o aumento em porcentagem no número de artigos comparado ao ano anterior, é possível observar que no período de 2002 a 2007 e os anos de 2009 e 2011 tiveram um aumento em média de 27% ao ano, a partir de 2012 o aumento continuou, porém com aumento em média de 10%.
O Big Data é considerada a nova tendência, porém como observado na Figura 11a, o Data Mining superou o número de artigos publicados. Os artigos que referenciam a Data Mining e Big Data tiveram um total de 120 artigos publicados nos anos de 2012 a 2014 (Scopus, 2015).
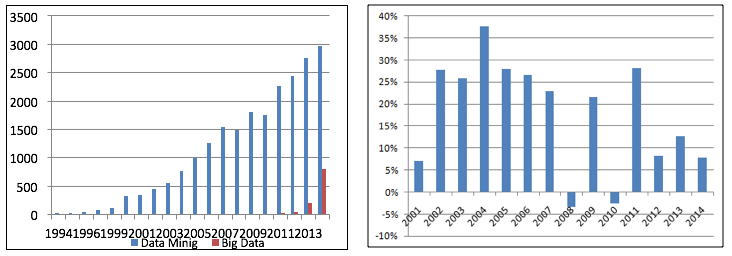
Figura 11 – a) Quantidade de artigos publicado por ano sobre "Data Mining" e "Big Data" b) evolução no aumento
do quantitativo comparado com o ano anterior sobre Data Mining. Fonte: SCOPUS (2015).
Para confirmar a tendência do tema Big Data foi realizada uma pesquisa no Google Trends que é uma ferramenta que informa a evolução na procura de termos nos portais em um determinado período de tempo. Na Figura 12 observa-se que a partir do ano de 2012 o termo "Big Data" obteve um aumento no interesse, já o termo "Data Mining" sofreu um desinteresse ao longo dos anos e partir de 2011manteve-se estável.
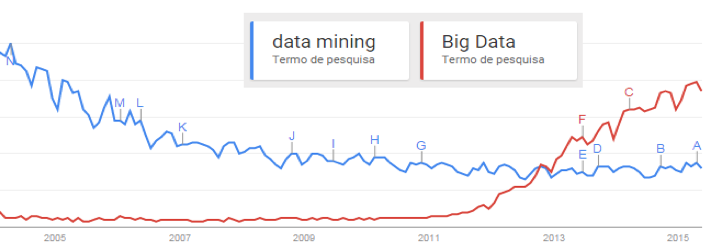
Figura 12 – Evolução na busca por termos "Data Mining" e "Big Data" na internet – Fonte: Google (2015).
Os computadores deixaram de ser meras ferramentas de apoio, e tornaram-se verdadeiros pilares no processo de desenvolvimento e criação de conhecimento e inteligência. Atualmente o acesso a tecnologia e informação não é mais privilégio das grandes empresas, esta disponibilização favorece a comunidade cientifica e acadêmica no que tange as inovações.
Este trabalho teve por objetivo mostrar as oportunidades e os novos desafios que a Gestão do Conhecimento pode oportunizar. Como já visto, a idéia principal é uma análise Bibliométrica, com os temas que tangem a Gestão do conhecimento e Descoberta do conhecimento, o trabalho também apresentou os conceitos já aceitos pelos pesquisadores, que é a descoberta de conhecimento em banco de dados (KDD), contudo também envolveu um nova área que atua com dados não estruturados, Denominado BIG DATA.
Na análise Bibliométrica foi possível identificar uma lacuna existente no que se refere a pesquisas, que envolvam a Gestão do conhecimento e a descoberta de conhecimento. Os artigos selecionados que trabalham com processos da Gestão do conhecimento tem a preocupação com a criação e aquisição de conhecimento, organização e armazenamento, distribuição e aplicação do conhecimento, no entanto, foi visto uma carência de trabalhos científicos que se preocupam com as atividades de descoberta de conhecimento. Outro fato relevante é que a descoberta de conhecimento tem três etapas: Pré-processamento, Mineração de dados e pós-processamento, porém a analise bibliométrica identificou que a maioria do artigos tem a preocupação dom apenas a etapa de Mineração de Dados, poucos artigos que tratam da etapa do pré-processamento e menor ainda o número de artigos que tratam do pós-processamento, isto é, a preocupação na visualização e interpretação dos resultados da mineração de dados.
Foi observado que dentre os artigos selecionado, os assuntos que tiveram o maior número de referencias, foram o uso de dados, tomada de decisão, utilização e desenvolvimento de software e algoritmos e uso dos dados das redes sociais e fóruns. Vale ressaltar que nesta avaliação os trabalhos que fazerm uso de dados e o uso da internet, demonstram o interesse de pesquisa no que se refere a dados não estruturados, mesmo não assumindo a nova área denominada BIG DATA, no entanto, contatou-se que trabalhos que envolvam a junção das etapas de descoberta de conhecimento com o BIG DATA na busca de conhecimento em dados disponíveis na Internet, apoiarão a construção de novas arquiteturas e modelos, e conforme observado existe uma carência de trabalhos no desenvolvimento de novas metodologias, framework e desenvolvimento de protótipos. É fato que os trabalhos práticos de descoberta e conhecimento envolvem processos interativos e iterativos, por este motivo a criação de protótipos se torna importante. O termo Interativo indica a atuação do Homem para a realização dos processos, sendo ele o responsável por utilizar as ferramentas computacionais para análise e interpretação dos dados. Para obter um resultado satisfatório, é necessário muitas vezes repetir o processo de forma integral ou parcial, ou seja, o processo é iterativo.
Por último foi possível constatar que o interesse no Big Data vem aumentando e que as pesquisas e interesse na área do Data Mining não chegou ao fim, como imaginava-se como surgimento do Big Data. Muitas pesquisas da descoberta de conhecimento podem ser utilizadas no Big Data e um novo termo já vem surgindo, denominado Big data analytics.
Archambault, E.; Campbell, D.; Gingras, Y.; Larivière, V. (2009). Comparing Bibliometric Statistics Obtained From the Web of Science and Scopus. Journal of the American society for information science and technology, 60(7),1320–1326.
Barthès, J. P. A. (1999). Can knowledge management be reduced to document management? Compiègne : University of Technology of Compiègne and Institut International pour l'Intelligence Artificielle URL: http://www.hds.utc.fr/~iiia/IIIA-public/IIIA-publications/IIIA-art98-jpb. Acessado em 20.04.2014
Begoli E. ; Horey J. (2012). Design Principles for Effective Knowledge Discovery from Big Data. In Proc. 2012 Joint WICSA/ECSA Conference, pages 215–218. IEEE, Tennessee, USA. Acessado em 26 de maio de 2014.
Breitman K. (2012) Big Data é indispensável ao pré sal. V Congresso Internacional Software Livre e Governo eletrônico.(Consegi )– Belém PA, 2012. Link: https://gestao.consegi.serpro.gov.br/sala_imprensa/sugestoes-de-entrevistas/big-data-e-indispensavel-ao-pre-sal. Acessado em 30 de out. de 2013.
Correa M. (2013) Uso de Big Data Ajuda Governo Brasileiro a Gastar de Forma Mais Eficiente –, link:<http://oglobo.globo.com/tecnologia/uso-de-big-data-ajuda-governo-brasileiro-gastar-de-forma-mais-eficiente-8582240> - Globo, 2013, Acessado em: 09 de maio 2014.
Dias, M. M. (2001) Um modelo de formalização do processo de sistema de descoberta de Conhecimento em banco de dados. 2001. Tese (Doutorado)-Pós Graduação em Engenharia de Produção, Universidade Federal de Santa Catarina. Florianópolis, Santa Catarina, 2001.
Fayyad, U.; Piatetsky S. G.; Smyth, P. (1996). The KDD process for extracting useful knowledge from volumes of data. Communications of the ACM, v. 39, no. 11, p. 27-35.
Feldens, M.A.; Moraes, R.L.; Pavan, A.; Castilho, J.M.V. (1998). Towards a methodology for the discovery of useful knowledge combining data mining, data warehousing and visualization. In: XXIV CLEI (Conferência Latino-Americana de Informática). Quito, Equador.
Gantz, J; Reinsel, D. (2012). The Digital Universe In 2020: Big Data, Bigger Digital Shadows, and Biggest Growth in the Far East. IDC.
Goebel, M.; Gruenwald, L. (1999) A Survey of Data Mining and Knowledge Discovery Software Tools. ACM SIGKDD Explorations, New York, v. 1, no. 1, p. 20-33, June. 1999.
Goldschmidt, R.; Passos, E. (2005). Data Mining um guia pratico. 1. ed. Rio de Janeiro: Campus.
GOOGLE TRENDS, Explore <http://www.google.com.br/trends/explore>: acessado em 20 de abril 2015.
IBM - What is big data? - Bringing big data to the enterprise, 2011 <www.ibm.com/software/data/bigdata> Acessado em 05 abril. 2015
Kobashi, N. Y.; Santos, R. N. M. (2006) Arqueologia do trabalho imaterial: uma aplicação bibliométria à análise de dissertações e teses. In: ENCONTRO NACIONAL DE PESQUISA EM CIÊNCIA DA INFORMAÇÃO,7, 2006, Marília. Anais... Marília: FFC/UNESP.
Manyika J.; Chui M.; Brown B.; Bughin J.; Dobbs R.; Roxburgh C.; Byers A. H. (2011). Big data: The next frontier for innovation, competition, and productivity. Technical report. EBook versions. McKinsey Global Institute, May 2011.
Mcafee, A; Brynjolfsson, E. (2012). Big Data: The Management Revolution -.Exploiting vast new fl ows of information can radically improve your company's performance. But first you'll have to change your decision-making culture. Business Review, edição de outubro de 2012.
Murray, P. (1996) C. New language for new leverage: the terminology of knowledge management (KM).
Murray. J. D.; Sevinc, M.; Locker L. (2005). Automation vs. Human Intervention: Is There any Room Left for the Analyst in the Data Mining Process? - Handbook of Research on Knowledge – Intensives Organizations. Information Science.. Hershey, New York.
Nonaka, I; Takeuchi, H. (1997) Criação de Conhecimento na Empresa. Rio de Janeiro: Campus.
Quinn, J. B.; Baruch, J. J.; Zien, K. A. (1997). Innovation explosion: using intellect and software to revolutionize growth strategies. New York : Free Press.
SCOPUS. Document Search. Disponível em: <http://www.scopus.com/home.url. Acesso em: 14 de maio de 2014.
Tarapanoff, K. (2001). Inteligência organizacional e competitiva. Brasília: Universidade de Brasília, (Org.) 2001.
WEBOFSCIENCE em http://webofknowledge.com acesso em 20 maio de 2014
Zikopoulos P. ; Eaton C. (2011). Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data. IBM - McGraw-Hill, Osborne Media 2011.
1. Professor mestre em Ciência da Computação e pesquisador na área de descoberta de conhecimento em banco de dados. Email: emerson.rabelo@ifpr.edu.br
2. Professor Doutor em Engenharia Mecânica e pesquisador na área de gestão da informação, conhecimento, novas Tecnologias Aplicadas à Gestão da Produção