 HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN
HOME | ÍNDICE POR TÍTULO | NORMAS PUBLICACIÓN Espacios. Vol. 37 (Nº 23) Año 2016. Pág. 30
Gerson do NASCIMENTO Silva 1; Fabiana LUCENA Oliveira 2
Recibido: 06/04/16 • Aprobado: 11/05/2016
3. Dados Cartográficos: Definição e Características
4. Modelagem de Dados Agrometeorológicos no Modelo Orientado a Documentos
RESUMO: O objetivo da cartografia é representar, utilizando-se símbolos qualitativos e/ou quantitativos, fenômenos localizáveis de qualquer natureza sobre uma base de referência, geralmente um mapa topográfico, em quaisquer escala, em que sobre um fundo geográfico básico, são representados os dados mais expressivos dos fenômenos climáticos, ambientais, hidrológicos, geográficos, geológicos, demográficos, econômicos, agrícolas e outros; visando ao estudo, à análise e a pesquisa dos temas, no seu aspecto espacial. Dessa forma, esse trabalho tem como foco o estudo do uso de banco de dados orientados a documentos e sem esquemas (Schema-Free Oriented-Document Databases) para o armazenamento de dados Cartográficos, do tipo Agrometeorológico (dados climáticos voltados para a agricultura), além de fazer uma breve abordagem sobre como transformar consultas escritas para banco de dados relacionais tradicionais em consultas para banco de dados orientados a documentos e/ou vice-versa (Marshall e Unmarshal entre as formas de consultas SQL e NoSQL). |
ABSTRACT: The objective of mapping is to represent, using quantitative and/or qualitative symbols locatable phenomena of any kind on a basis of reference, usually a topographic map at any scale, in which over a basic geographic background, more data are represented expressive of extreme weather, environmental, hydrological, geographical, geological, demographic, economic, agricultural and others seeking to study, research and analysis of themes in its spatial aspect. This work focuses on studying the use of database-driven documents and schema (Schema-Free-Oriented Databases Document) for storing cartographic data, the type Agrometeorological (climatic data-oriented agriculture), also make a brief discussion on how to transform queries written for traditional relational database in queries to database-driven documents and / or otherwise (Marshall and Unmarshal between forms of SQL queries and NoSQL). |
A Associação Cartográfica Internacional (International Cartographic Association. Disponível em: <http://icaci.org/>), define cartografia: "Cartografia é o conjunto de estudos e operações científicas, artísticas e técnicas, baseado nos resultados de observações diretas ou de análise de documentação, com vistas à elaboração e preparação de cartas, projetos e outras formas de expressão, assim como a sua utilização". Seu objetivo é representar, utilizando-se símbolos qualitativos e/ou quantitativos, fenômenos localizáveis de qualquer natureza sobre uma base de referência, geralmente um mapa topográfico, em quaisquer escala, em que sobre um fundo geográfico básico, são representados os fenômenos climáticos, hidrológicos, pluviológicos, geológicos, demográficos, econômicos, agrícolas e outros; visando ao estudo, à análise e a pesquisa dos temas, no seu aspecto espacial.
Nesse contexto, surgem os bancos de dados orientados a documentos e sem esquemas, como um modelo de armazenamento para grandes massas de dados – petabytes de informações. O que torna algumas implementações desse modelo tão atraentes é o fato de implementarem Google MapReduce; através da API denominada RESTful para consulta e manipulação de dados, que em sua essência, é um algoritmo para processamento de grandes volumes de dados.
Assim sendo, será utilizado o Apache CouchDB – uma implementação de código aberto do Google BigTable; para viabilizar o estudo do uso de banco de dados orientados a documentos para armazenagem de dados Cartográficos; visando elucidar possíveis dúvidas referentes ao manuseio desse modelo de armazenamento para dados geográficos do tipo Agrometeorológico (dados climáticos voltados para a agricultura).
O CouchDB foi criado em 2005 por Damien Katz, escrito originalmente na linguagem de programação C++ e traduzido para a linguagem de programação Erlang em 2008. Este mescla um modelo intuitivo de armazenagem em documentos com um poderoso sistema de pesquisa acessível via API REST e HTTP/JSON. Dentre as suas funcionalidades está à replicação bidirecional com detecção de falhas e resolução de conflitos; sua base de dados é fundamentada em MapReduce, e em vez de armazenar dados em linhas e colunas, o CouchDB gerencia uma coleção de documentos – os "JSON Documents"; e usa um processo de visualização com funções definidas que agregam dados e filtros para serem computados em paralelo.
Conforme Lennon (apud OLIVEIRA, 2009, p.19):
O termo Couch é um acrônimo para – Cluster of Unreliable Commodity Hardware (Conjunto de Hardware Não-Confiáveis), refletindo o objetivo do banco de dados ser extremamente escalável, oferecendo alta disponibilidade e confiabilidade, mesmo quando executando em um hardware que é tipicamente suscetível à falhas.
Segundo Fielding (Fielding R. T., 2000), o REST serve-se do HTTP como elemento integrante de sua arquitetura, deste modo, proferir que o CouchDB possui uma API REST expressa que o banco de dados está preparado para auferir requisições de um navegador (browser) ou qualquer outro cliente que implemente o protocolo HTTP.
O CouchDB não é uma substituição para os bancos de dados relacionais. Sua implementação também não é um banco de dados orientado a objetos, muito menos uma camada orientada a objetos para persistência de dados (Apache CouchDB, Introduction to CouchDB, 2008).
Para a arquitetura de documentos CouchDB, um documento é um objeto miscigenado de campos nomeados. Estes campos podem ser cadeias de caracteres, números, datas ou até listas ordenadas e mapas associativos (Hash Maps), onde não há limitação de tamanho para campos (Apache CouchDB, Introduction to CouchDB, 2008).
Segundo Lennon (apud OLIVEIRA, 2009, p.21):
Os dados estão prontos para armazenamento, ao invés de distribuídos entre colunas e linhas ao longo de arquivos de banco de dados. Quando os documentos são salvos no disco, seus campos e metadados são armazenados em buffers, de forma sequencial, um após o outro.
Os documentos são a menor unidade de dados dentro do CouchDB, e ao mesmo tempo são utilizados para armazenamento de metadados do banco. As operações de edição (adicionar, editar e remover) no CouchDB são atômicas, onde deve haver sucesso completo ou falha completa durante a operação, sempre garantindo que o banco de dados nunca irá armazenar documentos salvos ou editados parcialmente (Apache CouchDB, Technical Overview, 2008).
De acordo com Härder e Rothermel (Härder & Rothermel, 1987), o termo ACID refere-se às características de atomicidade, consistência, isolamento de execução e durabilidade (Atomicity, Consistency, Isolated Execution, Durability), que asseguram que transações de bancos de dados são processadas com confiabilidade. No CouchDB, todo o desenho (layout) de arquivos e sistema de persistência (commit) está fundamentado nestes princípios, o que deriva na garantia de uma situação sempre consistente do arquivo de banco de dados. O CouchDB utiliza um modelo baseado no algoritmo MVCC (Multiversion Concurrency Control), onde cada cliente vê um retrato consistente do banco de dados do começo até o final da operação de leitura (Apache CouchDB, Technical Overview, 2008).
Conforme Katz (Katz, 2008), os bancos de dados gerenciados pelo CouchDB crescem a cada atualização de documento, ainda que estas atualizações sejam remoção de documentos. Para recuperar espaço em disco, tem-se que efetuar um processo de compactação do banco de dados, que irá limpar todas as revisões anosas feitas a um documento e reorganizá-los no disco para viabilizar um acesso sequencial mais rápido.
Em sua padronização, o CouchDB proporciona dois tipos de permissão de acesso: administrador e leitura. O acesso de administrador possui autoridade total sobre as operações administrativas do banco – compactação, gerenciamento de visões e replicação, sendo capaz igualmente de criar outras contas administrativas. Para controlar o acesso de leitura, o CouchDB possui um documento que contém um inventário de usuários que podem acessar e alterar documentos protegidos. Este inventário de acesso também é estendido para as visões, onde caso um documento esteja protegido, este não será incluído no processamento pelo MapReduce.
O CouchDB precariza a consistência para priorizar a tolerância a falhas e a disponibilidade, por meio do particionamento de dados por diversos servidores, admitindo que um cliente continuamente acesse uma versão dos dados; desta forma, existe consecutivamente uma consistência fortuita da informação armazenada (Apache CouchDB, 2008). Para entender melhor os mecanismos de replicação utilizados pelo CouchDB, esta seção proporciona as considerações e estruturas empregadas pelo CouchDB para armazenamento e recuperação de dados em múltiplos nós.
De acordo com Lennon (Lennon, 2009), a administração do CouchDB pode ser desempenhada por várias APIs REST, que são implementadas por diversas linguagens de programação – como Ruby, Python e Java, mas também pela interface de administração que é aprovisionada juntamente com o banco de dados, de nome Futon. O Futon é uma aplicação que trabalha unicamente com navegadores (Browsers) que sejam capazes de interpretar a linguagem de programação JavaScript e realizar consultas por meio de requisições assíncronas com JavaScript utilizando a tecnologia AJAX. Assim como o navegador implementa o protocolo HTTP, este do mesmo modo é capaz de manusear documentos em um banco de dados CouchDB por meio dos métodos GET, PUT, POST e DELETE.
Dentro da interface do CouchDB, pode ser dado ênfase a determinadas telas que fazem as principais funções no banco de dados, como se pode verificar nas figuras (Figura 1 e Figura 2). Nesta seção serão apresentados os pontos positivos e contraproducentes desta interface.
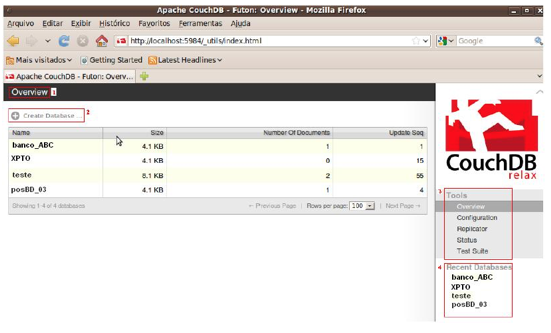
Figura 1 – Interface do Futon, uma aplicação de gerenciamento coligada ao CouchDB.
Na figura acima (Figura 1), pode-se constatar determinados retângulos com pequenos números começando pelo número um e terminando no número quatro, abaixo segue a significação dos mesmos, a saber:
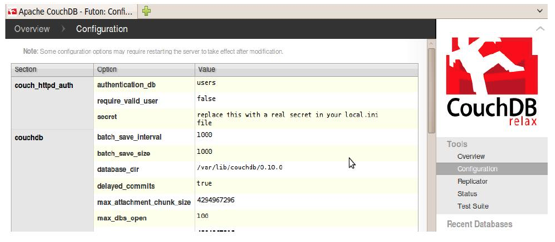
Figura 2 – Interface do Futon para a opção de Configuração do CouchDB.
Conforme ARONOFF (1989) e BORGES (1997) "dados espaciais são quaisquer tipos de dados que descrevem fenômenos aos quais esteja associada alguma dimensão espacial". A comedimento observado de um fenômeno, evento ou ocorrência sobre / sob a superfície terrestre é cognominado dado geográfico. "Dados geográficos ou georreferenciados são dados espaciais em que a dimensão espacial está associada à sua localização na superfície da Terra, num determinado instante ou período de tempo" (CAMARA et al, 1996).
De acordo com ROSA (2002) "dados geográficos ou georeferenciados significam fatos, objetos, fenômenos que ocorrem sobre a superfície terrestre e que possuem uma alta correlação com a sua localização sobre a superfície do globo terrestre, em um dado instante ou período de tempo". Essa perspectiva está retratada na figura abaixo (Figura 3):
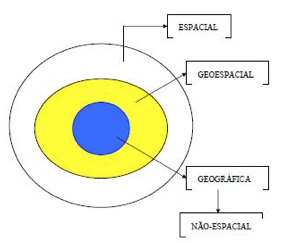
Figura 3 – Da visão espacial à geográfica (apenas ilustrativa, não está em escala).
Segundo Cavalcanti (Cavalcanti, 2009), a importância dos dados cartográficos tem sido expressiva – organizando, disponibilizando e propiciando a ampliação do conhecimento geográfico das nações. Vêm ainda corroborando com a tomada de decisão ambiental estratégica para gestão e desenvolvimento social e econômico, e fazendo parte da filosofia mundial de acesso à informação geográfica para todos.
Conforme Goodchild (Goodchild, 1992), os modelos formais para representação de dados geográficos, distinguem-se dois tipos principais de representação, a saber:
Estes são mapeados para estruturas de dados de duas naturezas: vetorial e matricial (ou raster).
Vinhas (Vinhas, 2006), afirma que o modelo de geo-campos enxerga o espaço geográfico como uma superfície contínua, sobre a qual variam os fenômenos a serem observados. Como exemplo, podem ser citados os mapas de vegetação e temperatura de uma determinada região geográfica. Um geo-campo representa um atributo que possui valores em todos os pontos pertencentes a uma região geográfica. Um geo-campo gc é uma relação gc = [R, A, f], onde R ![]() 2 é uma partição conexa do espaço, A é um atributo cujo domínio é D(A), e a função de atributo f: R → A é tal que, dado p
2 é uma partição conexa do espaço, A é um atributo cujo domínio é D(A), e a função de atributo f: R → A é tal que, dado p ![]() R, f(p) = a, onde a
R, f(p) = a, onde a ![]() D(A). As duas figuras abaixo mostram suas formas de representação (Figura 4 e Figura 5):
D(A). As duas figuras abaixo mostram suas formas de representação (Figura 4 e Figura 5):

Figura 4 – Representação de geo-campos (a altimetria de uma região): Matricial. Fonte: (Vinhas, 2006)
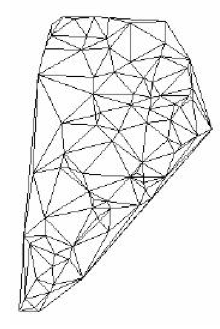
Figura 5 – Representação de geo-campos (a altimetria de uma região): Vetorial. Fonte: (Vinhas, 2006)
A componente espacial representada sob a forma de geo-campos é usualmente classificada nos seguintes tipos (Vinhas, 2006):
Vinhas (Vinhas, 2006), assegura que o modelo de geo-objetos, por sua vez, representa o espaço geográfico como uma coleção de entidades individualizadas distintas, onde cada entidade é definida por uma fronteira fechada. Um geo-objeto é uma entidade geográfica singular e indivisível, caracterizada por sua identidade, suas fronteiras, e seus atributos. Um geo-objeto é uma relação go = [id, a1,...an, G], onde id é um identificador único, G é um conjunto de partições 2D conexas e distintas {R1,...,Rn} do espaço ![]() 2, e ai são os valores dos atributos A1,...,An. Note-se que um geo-objeto pode ser composto por diferentes geometrias, onde cada geometria tem uma fronteira fechada (e.g., o Japão com suas diferentes ilhas).
2, e ai são os valores dos atributos A1,...,An. Note-se que um geo-objeto pode ser composto por diferentes geometrias, onde cada geometria tem uma fronteira fechada (e.g., o Japão com suas diferentes ilhas).
As duas figuras que seguem mostram suas formas de representação (Figura 6 e Figura 7):
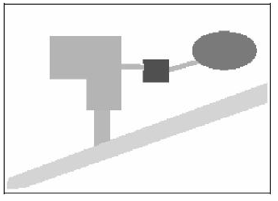
Figura 6 – Conjunto de geo-objetos (duas construções e um lago próximo a uma estrada): Matricial. Fonte: (Vinhas, 2006)
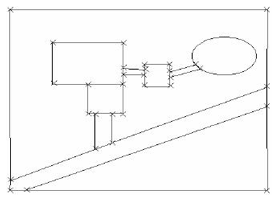
Figura 7 – Conjunto de geo-objetos (duas construções e um lago próximo a uma estrada): Vetorial. Fonte: (Vinhas, 2006)
A componente espacial representada sob a forma de geo-objetos normalmente se especializa nos seguintes tipos elementares da geometria plana (Vinhas, 2006):
As três figuras que seguem (Figura 8, Figura 9 e Figura 10) expressam os respectivos tipos elementares da geometria plana supracitada, a saber:
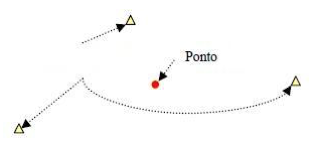
Figura 8 – Exemplo de representação geográfica com uso de ponto. Fonte: (Vinhas, 2006)
Figura 9 – Exemplo de representação geográfica com uso de linha. Fonte: (Vinhas, 2006)
Figura 10 – Exemplo de representação geográfica com uso de polígono. Fonte: (Vinhas, 2006)
De acordo com Uschold and Grüninger (Uschold and Grüninger,1996), uma ontologia é uma consideração formal, explícita e compartilhada de alguma área do conhecimento, igualmente chamado de domínio de discurso. Deste modo, uma ontologia consiste de conceitos e relações, com propriedades e restrições delineadas sob a forma de axiomas.
Aproveitar-se de ontologias para dados geográficos convém quando se tem situações práticas de demarcação de um dicionário prosaico para delinear a esfera geo-espacial que pode promover a interoperabilidade e atenuar dificuldades de integração de dados (Agarwal, 2005 and Fonseca et. al., 2002).
Conforme Harpal & Tupper (Harpal & Tupper, 2004), é possível demonstrar qual é o âmbito e natureza da Agrometeorologia, consubstanciados nas relações entre o clima (a meteorologia e hidrologia) e a agricultura, na sua acepção mais geral. A figura abaixo (Figura 11), ilustra essa relação, a saber:
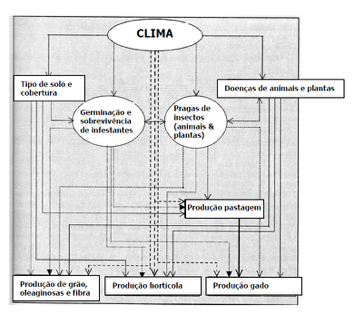
Figura 11 – Relações entre o clima e a produção agrícola. Fonte: (Harpal & Tupper, 2004)
Conforme Florenzano (Florenzano 2002), na era moderna, as técnicas de coleta, processamento e análise de dados meteorológicos evoluíram velozmente. Com o progresso da tecnologia da informação e o advento das geotecnologias, quanto maior o número de informações meteorológicas globais, regionais e locais, maior é a probabilidade de sucesso do planejamento agrícola. A representação de dados climáticos no espaço é de fundamental importância em diversas áreas do conhecimento, sendo de uso extensivo nas áreas de agronomia, biologia, ecologia, geografia, geologia e meteorologia.
Veja-se, a seguir, um exemplo (Gráfico 1) proposto por Correia (Correia et al., 2002), e que demonstra a importância do dado Agrometeorológico; admitindo um cenário para Portugal, os balanços hídricos sequenciais mostram que os anos agrícolas de 1999 e 2000 foram os que apresentaram os períodos com déficits hídricos mais longos e acentuados, especialmente o ano agrícola de 1999 quando o período seco teve início em setembro, se prolongando até outubro, e outro período seco ocorreu em dezembro.
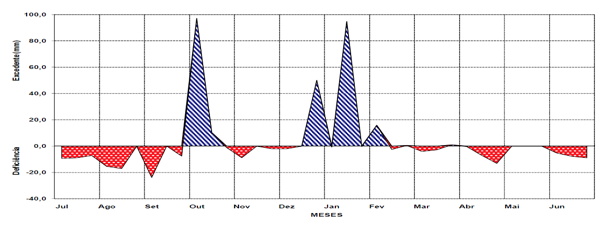
Gráfico 1 – Extrato do balanço hídrico normal (1999/2000) para Portugal. Fonte: (Correia et al., 2002).
Conforme Anderson e outros (Anderson, et al., 2009), bancos de dados orientados a documentos empregam o conceito de dados e documentos autocontidos e autodescritivos, isso sugere que o documento em si já resolve como ele deve ser apresentado e a definição dos dados em cuja sua estrutura estão contidos. Os autores mostram que muitas vezes a forma como o modelo deve ser projetado, de acordo com seu paradigma, muitas vezes não traduz a forma como um programador gostaria de ter seus dados persistidos.
Anderson e outros (Anderson, et al., 2009) asseguram que durante o procedimento de modelagem relacional, uma das premissas é a identificação singular de registros. Os autores definem que uma chave natural é a coleção de colunas que identificam uma tupla como única dentro de uma tabela e que uma forma de facilitar a criação de chaves únicas em uma tupla, ao invés da utilização de chaves naturais está na atribuição de um identificador numérico único para cada tupla. A maior parte dos bancos de dados relacionais provê estruturas chamadas de sequências (Sequences), que podem imputar automaticamente estes identificadores numéricos a uma tupla.
Para resolver o problema das sequências (Sequences), os bancos de dados orientados a documentos e sem esquemas podem valer-se do conceito de identificadores únicos universais (Universally Unique Identifiers ou apenas UUID), onde Anderson e outros (Anderson, et al., 2009) ressaltam que a probabilidade de abruptamente empregar um mesmo identificador que outro banco de dados é efetivamente zero. Os identificadores únicos universais são conferidos como identificadores do documento, que carecem serem exclusivos dentro de um banco de dados orientados a documentos.
FIELDING (2000) afirma que pelo caso de empregar um modelo arquitetural RESTful (fundamentado no REST) e por este servir-se do protocolo HTTP e do paradigma da Web como embasamento, a escalabilidade de um banco de dados orientado a documentos é uma decorrência de seu emprego.
A norma ISO/IEC 9075-1:2008 (International Organization for Standardization, 2008.Disponível em < http://www.iso.org>) define a linguagem SQL, até mesmo constituindo um critério ínfimo de adoção para tornar a linguagem unânime. No entanto, os múltiplos fabricantes de bancos de dados desdobram a linguagem SQL, instituindo dialetos próprios (Arvin, 2009), o que faz com que a eficácia genérica do SQL permaneça exclusivamente no nível pequeníssimo que a norma define.
Neste estudo de caso, será empregado o uso de abstração para o projeto lógico e físico (criação de tabelas, índices, gatilhos, asserções, visões, pacotes, tipos, procedimentos e outros) de um banco de dados relacional; que neste caso especifico, será empregado o MySQL. Será utilizado ainda, abstração para uma visão do banco de dados relacional MySQL de nome "DadosClimaticos", que contém os campos (Temperatura, Umidade, Pluviosidade, Data, Município, Localização e Estado) utilizados pelo experimento para demonstrar como fazer a transcrição entre a forma de consulta SQL e NoSQL.
Como contrapartida NoSQL, empregar-se-á o Apache CouchDB como banco de dados não-relacional e orientado a documentos, como também o uso de abstração para a visão de nome "DadosClimaticos", que contém os campos (Temperatura, Umidade, Pluviosidade, Data, Município, Localização e Estado) – também requerida por este experimento.
O MAPA - Ministério da Agricultura, Pecuária e Abastecimento serve-se das Unidades Federativas do Brasil e de seus mais de 5.500 municípios para efetuar leituras climatológicas relativas à temperatura, umidade, pluviosidade e/ou outras variáveis que devem ser representadas no banco de dados deste experimento, conforme lista abaixo:
Neste estudo de caso, cada variável é representada de forma singular, o que exige uma estrutura de documento especifica para poder representá-las, como segue abaixo:
a) Estrutura do documento, valorada como exemplo, utilizada para representar o fragmento do espaço amostral das variáveis estudadas:
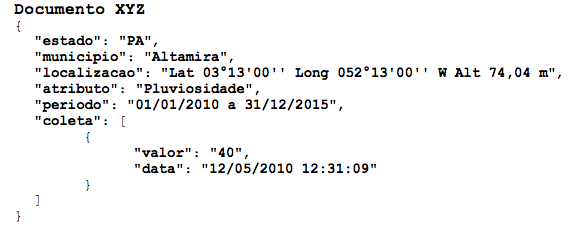
Para o referido experimento, segue a respectiva modelagem conceitual, empregando o modelo Entidade-Relacionamento.
Esta modelagem retrata apenas um simples fragmento do espaço amostral correspondente aos das variáveis pesquisadas, e por isso não deve ser avaliada como representante de todo o referido espaço amostral.
Veja-se, a seguir, um diagrama ER que pode representar o fragmento do espaço amostral estudado (Figura 12):
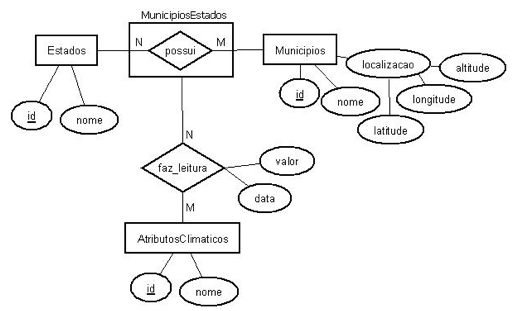
Figura 12 – Diagrama ER – retrata modelagem do espaço amostral das variáveis georreferenciadas estudadas no Centro de Sementes Nativas do Amazonas.
Para que seja possível extrair as informações de um banco de dados orientado a documentos, faz-se necessário escrever suas respectivas funções de mapeamento e redução (MapReduce), para cada tipo de consulta desejada. A tabela abaixo (Tabela 1) retrata como se efetuar a transcrição de uma consulta escrita em SQL para NoSQL e/ou vice-versa. Veja-se, agora, na tabela que segue, o código de consulta escrita em linguagem de programação SQL – voltada para o SGBDR MySQL, e sua correspondente escrita em linguagem de programação NoSQL – voltada para o SGBDOD CouchDB
Tabela 1 – Marshall e Unmarshal entre as formas de consulta SQL e NoSQL.

Tabela 2– Legenda relativa às cores empregadas para a transcrição (Marshall) das formas de consulta SQL para NoSQL.

Para exemplificar a aplicação de bancos de dados orientados a documentos para armazenamento de dados cartográficos do tipo agrometeorológico, foi realizado um estudo de caso que focou seu objetivo na construção da função de mapeamento e redução (MapReduce); visando explicitar seu emprego e potencial para acomodar qualquer tipo de dado. Em contrapartida, foi verificado que existe certa complexidade da modelagem voltada para bancos de dados orientados a documentos, como também o manuseio e compreensão de MapReduce; pois torna-se oneroso (em termos de tempo) para equipes que ainda não estejam versadas na implementação da API REST; devido ao fato da curva de aprendizado ser íngreme.
É importante ressaltar a heterogeneidade do formato em que os dados se apresentam – isso dificulta o entendimento e modelagem no âmbito dos bancos de dados orientados a documentos.
Pelo fato dos SGBDODs empregarem a filosofia de dados autocontidos, a significação do que compõe o documento já está revelada como um todo, sem menção a dados externos. As diferenças importantes são igualmente percebidas no compartilhamento global, onde nos SGBDODs a conceituação de arquitetura sem compartilhamento (Shared-Nothing Architecture) é aproveitada, não obstante as altercações durante o processamento de uma transação, devido ao caso dos SGBDODs não se servirem de bloqueios e outras características arquiteturais, como persistência (Cacheing) que existe em nível de protocolo HTTP.
Durante o experimento, um diminuto comparativo entre os bancos de dados relacionais (SQL) e sua contrapartida não-relacional e orientada a documentos (NoSQL) foi exposto, onde as fundamentais diferenças estão na modelagem dos dados, pois nos SGBDRs é imprescindível a granulação das informações em diferentes tabelas, ligando-as por intermédio do conceito de chaves estrangeiras.
Como resultado, percebe-se que a flexibilidade de documentos faz sentido em domínios em que os dados podem ser representados de formas diversas, mas com o mesmo modelo fundamental. Um exemplo costumeiro é um cartão de visita. Dada uma pilha de cartões de visita, se verá que eles proporcionam dessemelhantes dados, mas o modelo, ou função, é o mesmo – cartões de visita contêm informações de contato.
Finalizando o estudo de caso, verifica-se que pode ser prematuro fazer-se uso de bancos de dados não-relacionais e orientados a documentos (NoSQL) para qualquer tipo de domínio – principalmente dados geográficos; pois o armazenamento com esquemas livres (Schema-Free) não é adequado para qualquer situação. Portanto, para que haja menos percalços no projeto, torna-se imprescindível entender quando se deve optar por uma abordagem não-relacionais e orientados a documentos (NoSQL) ao oposto de uma abordagem relacional tradicional (SQL).
Neste trabalho foi exposto o estudo do uso de banco de dados orientados a documentos e livre de esquemas (Schema-Free Oriented-Document Databases) para armazenagem de dados cartográficos do tipo agrometeorológico (dados climáticos voltados para a agricultura), onde se identificou que documentos são largamente empregados em corporações, mas o seu uso como modelo de estrutura e armazenamento de dados só tornou-se notório com o desenvolvimento cada vez mais ascendente da Web e os diminutos custos de hardware. Desse modo, a obrigação de criação de um moderno paradigma de modelagem, armazenamento, consulta e apresentação de dados para conjeturar a estrutura de um documento do mundo real tornou-se manifesta.
O paradigma alvitrado e utilizado pelo experimento é implementado pelo Apache CouchDB, um banco de dados orientado a documentos – distribuído, livre de esquema e manipulável por meio de uma API REST. O Apache CouchDB é uma implementação de importância com sofisticados conceitos no que diz respeito a este emergente paradigma de modelagem e armazenamento de dados.
Percebe-se como uma oportunidade de trabalhos futuros, o estudo de viabilidade de emprego do paradigma implementado pelos SGBDODs como consistência eventual, replicação e consultas com MapReduce voltados para dispositivos móveis, onde o seu manuseio no dia-a-dia adquire papéis semelhantes aos exercidos por documentos. Igualmente pode ser identificado uma melhor metodologia para se projetar sistemas orientados a documentos e encontrar padrões de criação de aplicações que empregam SGBDODs.
Finalizando, pode-se expressar que o Apache CouchDB é um excelente banco de dados. É um paradigma emergente que está se desenvolvendo rápido, graças a sua consistência. Seu arcabouço documental enriquece gradualmente junto com seus grupos de discussões e sítios (sites) com informações sobre as suas funcionalidades. Entretanto, pode não ser a melhor opção para armazenagem e recuperação de dados geográficos, visto que o armazenamento com esquemas livres não é adequado para qualquer situação.
ANDERSON, J. C., Lehnardt, J., & Slater, N. (2009).
CouchDB: The Definitive Guide, 1st Edition. Sebastopol, California: O'Reilly Media, Inc.
AGARWAL, P. Ontological considerations in GIScience. Int'l Journal of Geographical Information Science.
APACHE, HTTP. Cassandra. Acesso em 14 de março de 2016, disponível em: http://cassandra.apache.org/
APACHE. HTTP. HTTP Document API. Acesso em 14 de março de 2016, disponível em CouchDB Wiki: http://wiki.apache.org/couchdb/http_document_api
APACHE. HTTP. Introduction. Acesso em 10 de março de 2016, disponível em Apache CouchDB: http://couchdb.apache.org/docs/intro.html
APACHE. HTTP. Technical Overview. Acesso em 13 de março de 2016, disponível em Apache CouchDB: http://couchdb.apache.org/docs/overview.html
APACHE. HTTP. Introduction to CouchDB views. Acesso em 14 de março de 2016, disponível em CouchDB Wiki: http://wiki.apache.org/couchdb/introduction_to_couchdb_views
FIELDING, R. T. Architectural Styles and the Design of Network-based Software Architectures. University of California Irvine.
GOODCHILD, M. F. Geographical Data Modeling. Computers and Geosciences.
HÄRDER, T., & Rothermel, K. Concepts for transaction recovery in nested transactions. ACM SIGMOD. New York: ACM.
INTERNATIONAL, Cartographic Association. HTTP. ICA. Acesso em 03 de janeiro de 2016, disponível em: http://icaci.org/
KATZ, D. HTTP. Compaction. Acesso em 14 de janeiro de 2016, disponível em: http://damienkatz.net/2008/04/compaction.html
LENNON, Joe. Begining CouchDB. USA: Apress.
ROSA, Everton. HTTP. Apache Cassandra. Acessado em 14 de janeiro de 2016, disponível em: http://dotinfo.wordpress.com/2010/04/03/dicas-l-Apache-cassandra-nosql-uma-tecnologia-emergente/
USCHOLD, M. and GRÜNINGER, M. Ontologies: Principles, Methods and Applications. Knowledge Engineering Review.
VINHAS, Lúbia. HTTP. Um Subsistema Extensível para o Armazenamento de Geo-Campos em Bancos de Dados Geográficos. 2006. 114 f. Tese (Doutorado) – Acesso em 16 de janeiro de 2016, disponível em: www.dpi.inpe.br/~lubia/TeseLubia.pdf
1. Especialização em Projeto e Administração de Banco e Dados pela Laureate International Universities (Manaus-AM). Graduado em Análise e Desenvolvimento de Sistemas pelo Centro Universitário do Norte (AM). Atua como Project Manager e Analista de Processos e de Negócios, utilizando os conhecimentos necessários para analisar, mapear, modelar, medir, implantar e acompanhar processos para melhoria da qualidade na organização, implantação de sistemas de TI, correções de não conformidades. MBA em Logística pela Universidade Federal do Amazonas - UFAM, possibilitando pensar e agir estrategicamente frente aos desafios da Logística e Supply Chain Management; com ênfase em Pesquisa Operacional (racionalização dos processos logísticos, o uso da tecnologia da informação, a valorização do capital humano, a negociação cooperativa, o aumento da produtividade, a identificação e redução de custos logísticos, em ambiente de comprometimento social e ambiental). E-mail: gerson_nascimento@ufam.edu.br / gerson.developer@gmail.com
2. Graduação em Ciências Econômicas pela Faculdade de Estudos Sociais da Universidade Federal do Amazonas (1997) e doutorado em Engenharia de Transportes pelo Instituto Alberto Luiz Coimbra de Pós-Graduação em Engenharia / UFRJ (2009). É professora adjunta e atualmente responde pela Coordenação do Curso Regular de Ciências Econômicas da Universidade do Estado do Amazonas. Tem experiência na área de Engenharia de Transportes, com ênfase em Planejamento de Transportes, atuando principalmente nos seguintes temas: estratégia empresarial, planejamento de transportes, logística empresarial, polo industrial de Manaus (PIM) e gestão de materiais. E-mail: flucenaoliveira@gmail.com