![]() ISSN 0798 1015
ISSN 0798 1015

![]() ISSN 0798 1015
ISSN 0798 1015
Vol. 41 (Nº 05) Año 2020. Pág. 25
ACOSTA, Adán 1; AGUILAR-ESTEVA, Verónica 2; CARREÑO, Ricardo 3; PATIÑO, Miguel 4; PATIÑO, Julián 5 y MARTÍNEZ, Miguel A. 6
Recibido: 07/11/2019 • Aprobado: 28/01/2020 • Publicado 20/02/2020
RESUMEN: La inteligencia artificial tiene múltiples aplicaciones en la sociedad logrando grandes avances en las nuevas tecnologías como la cadena de bloques. Hasta ahora son las estrategias más innovadores y potentes para el diseño de arquitecturas que proporcionan al entorno de internet seguridad y confiabilidad en el procesamiento masivo de datos. El objetivo de este artículo es proporcionar una visión general de las arquitecturas utilizadas en sistemas tradicionales y descentralizados empleando herramientas de la inteligencia artificial aplicando la metodología del mapeo sistemático. |
ABSTRACT: Artificial intelligence has multiple applications in society achieving great advances in new technologies such as blockchain. So far they are the most innovative and powerful strategies for the design of architectures that provide the internet environment with security and reliability in the massive data processing. The objective of this article is to provide an overview of the architectures used in traditional and decentralized systems using artificial intelligence tools applying the methodology of systematic mapping. |

El rápido desarrollo de Internet y con ello, el impulso de tecnologías ha llevado a un crecimiento impresionante de los datos que se procesan en casi todas las áreas de la industria, desencadenando un acelerado cambio en temas relacionados con la inteligencia artificial procesando grandes volúmenes de datos (Jin, Wah, Cheng, y Wang, 2015). Las tecnologías son una solución óptima para resolver problemas que el ser humano no sería capaz de hacer debido a las limitaciones en la capacidad de retención de información y procesamiento de la misma, por ello es importante explorar y seleccionar las opciones más capaces que se tienen al alcance para la resolución de problemas.
La cadena de bloques es una tecnología que se introdujera inicialmente para el pago entre pares, pero desde entonces ha quedado claro que ésta nueva tecnología se puede usar para múltiples aplicaciones. Uno de estos nuevos usos es la ejecución de los llamados contratos inteligentes que está cambiando drásticamente la forma en que la tecnología y el conocimiento se producen en la sociedad (Dattakumar y Sharma, 2016; Weingart, 2011) teniendo un impacto de magnitud trascendental, no solo en este campo, sino también en la reestructuración de la forma en que las sociedades se organizan para producir bienes y/o servicios.
Es necesario reconocer la importancia y los retos del proceso en el que el conocimiento y la transferencia de tecnología están reestructurando radicalmente a un entorno en el que el conocimiento, siendo cada vez más accesible de manera masiva, abierta y de bajo costo, puede ser una solución. Las tecnologías de comunicación e información (TIC), dan lugar a una transferencia de tecnología que impregna fácilmente cualquier punto geofísico de una manera muy accesible, sin grandes obstáculos, como las barreras conocidas para la centralización del conocimiento. El nuevo paradigma de la descentralización del conocimiento es el soporte de la nueva revolución industrial, no menos trascendente que la ocurrida después de la invención de Internet.
Un aspecto fundamental que deben de integrarse en los retos de la inteligencia artificial y la sociedad del conocimiento (Krüger, 2006; Montero y Gewerc, 2018; Valdés y Gutiérrez-Esteban, 2018) son: la necesidad de procesar una gran cantidad de información disponible en los medios masivos y tecnológicos que permiten el acercamiento al conocimiento; la dificultad para la selección adecuada de fuentes confiables; el uso adecuado del conocimiento difundido en los medios masivos; el efecto de la saturación de información y datos con la capacidad de retención y análisis de información para generar nuevo conocimiento.
En este sentido, el propósito de esta investigación sistemática es ofrecer una visión general respecto a tecnologías, técnicas y métodos documentadas sobre la inteligencia artificial y los retos que conlleva en la sociedad para la resolución de problemas en entornos centralizados y descentralizados sirviendo como punto de partida para la investigación de estas nuevas arquitecturas y de futuras investigaciones.
La técnica metodológica del mapeo sistemático se define como un proceso y una estructura de informe que permite categorizar los resultados que han sido publicados por expertos hasta el momento en un área del conocimiento determinada. El objetivo de un mapeo sistemático está orientado a la clasificación de un tema en particular, está por tanto dirigido al análisis e identificación de los principales hallazgos publicados. Permite responder preguntas genéricas como ¿Qué es lo que se ha hecho hasta el momento en el campo disciplinario del tema en particular?, ¿hasta dónde se ha trabajado en la frontera del conocimiento?. El proceso de mapeo sistemático consista de las siguientes etapas: a) definir las preguntas de investigación; b) cual es el ámbito de la revisión; c) ejecución de la búsqueda; d) selección de documentos; e) filtrado de estudios; f) clasificación; g) extracción de datos y; h) mapa sistemático (Petersen, Feldt, Mujtaba, y Mattsson, 2008).
Las preguntas de investigación (Tabla 1) se definieron con base a los objetivos que fueron planteadas en la revisión sistemática recomendado por Kitchenham y Charters (2007) con respecto a las nuevas tecnologías empleadas como factor de cambio ante los retos de la inteligencia artificial y la sociedad del conocimiento.
Tabla 1
Preguntas de investigación
No. |
Preguntas |
1 |
¿Qué son los sistemas descentralizados y cuáles son sus características? |
2 |
¿Qué es un contrato inteligente? |
3 |
¿Qué es y cuáles son las características de los sistemas centralizados? |
4 |
¿Qué son las redes neuronales y cuáles son sus principales modelos? |
5 |
¿Cuáles son las principales técnicas de segmentación relacionados con la inteligencia artificial? |
6 |
¿Qué arquitecturas y componentes con respecto al procesamiento masivo de datos se han diseñado para solucionar problemas? |
7 |
¿Cuáles son las herramientas más utilizadas en el procesamiento de gran cantidad de datos? |
El alcance del ámbito de la revisión se definió de acuerdo a lo recomendado por Kitchenham y Charters (2007), de acuerdo a la población de investigadores en la frontera del conocimiento con respecto a sistemas centralizados y descentralizados; de acuerdo a la intervención de cualquier estudio que contenga la descripción de arquitecturas de redes neuronales, inteligencia artificial, gran cantidad de datos (big data) utilizados en internet y el resultado, así como las características principales de las arquitecturas encontradas.
La estrategia de búsqueda consistió en palabras y expresiones formadas por las siguientes palabras claves, tanto en español como en inglés: redes neuronales (neural networks), inteligencia artificial (artificial intelligence), sociedad del conocimiento (knowledge society), datos grandes (big data), sistemas descentralizados (decentralized systems), sistemas centralizados (centralized systems), contatos inteligentes (smart contract) arquitectura EOSIO (EOSIO architecture), arquitectura Ethereum (Ethereum architecture), internet de las cosas (internet of things), las cuales se generaron a partir de las preguntas de investigación planteadas, es así que la cadena de búsqueda básica se construye a partir de las palabras claves mencionadas. Se utilizó una búsqueda avanzada para encontrar los títulos y las palabras claves, debido a que interesa investigar los trabajos que declaran haber evidencia teórica al respecto de los temas de interés.
El criterio utilizado para la selección de documentos analizados en esta investigación consistió en la utilización de las siguientes bases de datos: Google Académico, WoS, Science Direct, Scielo, Redalyc y Latindex con el fin de seleccionar artículos de revistas indexadas y arbitradas. Durante el proceso de búsqueda se encontraron un número considerable de investigaciones pertinentes, sin embargo, se procedió a seleccionar 3865 trabajos, con el fin de estructurarlos y obtener una base de conocimiento de calidad (Berners-Lee, Hendler, y Lassila, 2001), los cuales fueron clasificados en tres tipos: artículos teóricos, artículos empíricos y libros.
La selección de los documentos se ha formulado con base a los siguientes criterios de inclusión/exclusión: a) inclusión, trabajos de investigación que provienen de revistas arbitradas e indexadas y de libros, relacionados directamente y otros que ayudan a contextualizar las preguntas de investigación (Tabla 2); b) exclusión, documentos y trabajos técnicos como tesis, noticias, reportajes o investigaciones con otro tipo de tecnologías. Para seleccionar los trabajos de investigación, en primera instancia utilizamos el criterio de inclusión para hacer análisis sobre el título, resumen y palabras claves, obteniendo de esta manera el mayor número de trabajos que aportan contribuciones significativas y de contextualización sobre las preguntas de investigación. En segunda instancia utilizamos el criterio de exclusión donde nos centramos principalmente en el resumen, introducción y conclusiones, analizando un poco más aquellos trabajos que lo requerían para asegurar que realmente eran irrelevantes para el campo de estudio.
Tabla 2
Documentos analizados en el estudio
Tipo |
Relacionados directamente con el tema |
De contextualización o complemento |
Artículos teóricos |
1257 |
741 |
Artículos empíricos |
986 |
564 |
Libros |
230 |
87 |
El proceso de selección consta de tres etapas realizadas secuencialmente por cuatro revisores. En la primera etapa, cada revisor aplicó los criterios de inclusión y exclusión para el título, resumen y palabras clave seleccionadas de forma aleatoria para los documentos seleccionados. Como medio de validación de concordancia entre los revisores se aplicó el índice Kappa de Fleiss (Gwet, 2002), obteniendo una fiabilidad del 85%. En la siguiente etapa, cada revisor aplicó los mismos criterios a un conjunto de artículos incluyendo la introducción y la conclusión, obteniendo un conjunto de trabajos candidatos. En la tercera etapa, fueron analizados los trabajos candidatos, de esta manera se determinó un total de 250 investigaciones pertinentes para el mapeo sistemático.
Una vez seleccionadas las publicaciones relevantes que se definieron en base a los objetivos del estudio que se plantearon con las siete preguntas de investigación, la clasificación fue de la siguiente manera; a) tipo artículo, si el trabajo fue publicado en una revista, en una conferencia o en un libro; b)Tipo de Problema: se refiere al tipo de problema que se resuelve con las arquitecturas relacionadas con el procesamiento de los datos (Big Data); c) aplicación: el área donde se desarrolla la investigación o donde registran los autores su contexto de aplicación, para esta investigación se definieron dos grandes segmentos; la academia, clasificada como aquellas publicaciones que dirigen sus esfuerzos en realizar investigaciones para el desarrollo de nuevas ideas; y la industria, en este estudio la clasificación corresponde a los trabajos que aplican su investigación en alguna organización y sirven para solucionar problemas específicos en la industria como sector productivo; d) Tipo de Arquitectura: se han definido tipos de arquitecturas de acuerdo al uso que se encontró: i) simplificación, se refiere a las arquitecturas que simplifican las cuestiones de desarrollo; ii) configuración e implementación, para sistemas centralizados que permiten la generalización de las redes inalámbricas, logrando una fácil interconexión con otras redes, una base de datos accesible para los gestores (dueños) de las plataformas, para el caso de los sistemas descentralizados se tiene una seguridad y confiabilidad en los datos ya que se ejecutan por medio de contratos inteligentes donde además la información de los datos esta encriptada; iii) reconfiguración, se refiere a que el sistema diseñado debe ser capaz de volver a configurarse de forma remota; e) componentes de la arquitectura: son todos los bloques que se han definido en los distintos niveles de la arquitectura. Los principales bloques que describen los estudios son: el de almacenamiento, procesamiento de datos, análisis de los datos, de sensores, de visualización de la información, y el de interconexión de sistemas; f) tipo de investigación: se encontraron los siguientes tipos de investigación, caso de estudios y experimentos; g) tecnología: Son todas las herramientas tecnológicas mencionadas en los trabajos analizados, para sistemas centralizados se encontraron las siguientes: Hadoop, Hbase, Linux, MongoDB, Plataforma HPC, RFID, GPS, Cosmos, Cluster, Mapreduce, Spark, VoltDB, CloudView, M2M, Exalead, Mysql, Mahout, Jaspersoft, Cloudera, Pentaho, Eclipse, ArcGis, Cloud, Radoop, Matlab, Rabbit MQ. Para el caso de sistemas descentralizados son: las cadenas de bloques.
Una vez definido el esquema de clasificación se detalla el mapeo sistemático, consistiendo en la extracción de datos y el proceso de mapeo de las distintas dimensiones. El resultado sintetizado del presente estudio se puede observar de manera gráfica en el diagrama de burbuja (Figura 1), donde se ilustra mediante un diagrama de dispersión XY con burbujas en las intersecciones de categoría, que permite tener en cuenta varias categorías al mismo tiempo y da una visión general rápida del campo de estudio, proporcionando un mapa visual. En esta visualización de los resultados, el tamaño de una burbuja es proporcional al número de artículos que están en el par de categorías que correspondan a la burbuja de las coordenadas.
Figura 1
Diagrama de burbuja
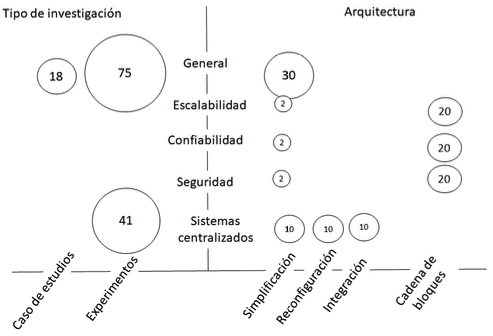
En la Figura 1, se visualiza el mapeo sistemático según el tipo de investigación y arquitectura, con relación a los problemas que se encuentran de manera general, y con los sistemas en cuanto a la escalabilidad, confiabilidad y seguridad que proporcionan a los usuarios, igualmente en este eje se muestra la relación de los sistemas centralizados. Se observa que las investigaciones encontradas con respecto a las cadenas de bloques representan una ventaja de escalabilidad, confiabilidad y seguridad respecto a las demás arquitecturas. Por otro lado, a razón del tipo de investigación se observa que se tiene gran cantidad de experimentos relacionados y configurados en plataformas tradicionales (sistemas centralizados).
A continuación, damos respuesta a las preguntas de investigación formuladas en la sección 2 a través de los principales resultados encontrados.
La descentralización no es un concepto nuevo, pero el auge de sus aplicaciones si lo es, se ha utilizado en estrategia, gestión y gobierno por mucho tiempo (Canales y Nanda, 2012). En este sentido la idea básicamente es distribuir el control y la autoridad a las periferias en lugar de que una autoridad central tenga el control sobre una organización determinada.
El concepto de descentralización que se aborda desde este estudio es el relacionado con la cadena de bloques vista como un vehículo perfecto que proporciona una plataforma que elimina a los intermediarios y funciona agregando múltiples lideres elegidos a través de mecanismos de consensos. Una verdadera innovación en el paradigma descentralizado que ha iniciado esta nueva era de aplicaciones de descentralización es el consenso descentralizado, que se introdujo con bitcoin (Bayer, Haber y Stornetta, 1993; Nakamoto, 1998). Esto permite al usuario acordar “algo” a través de un algoritmo de consenso sin la necesidad de un tercero, un central, intermediario o proveedor de servicios, proporcionando a los usuarios seguridad, confiabilidad y escalabilidad por medio de las plataformas desarrolladas.
Los contratos inteligentes fueron teorizados por primera vez por Ninck Szabo a finales de la década de 1990, pero pasaron casi 20 años antes de que el verdadero potencial y los beneficios que proporcionan lograran permear, un contrato inteligente es un programa que se ejecuta en la cadena de bloques y tiene su ejecución correcta aplicada por el protocolo de consenso (Szabo, 1997). Un contrato inteligente también es definido por Sillaber y Waltl (2017) como un protocolo de transacción que ejecuta los términos de un contrato, cuyos objetivos generales son satisfacer las condiciones contractuales comunes: condiciones de pago, confidencialidad y cumplimiento, con el fin de minimizar las excepciones maliciosas y accidentales, así como también minimizar la necesidad de intermediarios. En términos económicos el objetivo de los contratos inteligentes está relacionado con la eliminación de los fraudes, los arbitrajes y los costos elevados de la ejecución comparado con los contratos tradicionales.
La tecnología de la información y la comunicación (TIC) se ha basado convencionalmente en un paradigma centralizado mediante el cual los servidores de bases de datos o aplicaciones están bajo el control de una autoridad central, como un administrador del sistema. Los sistemas centralizados son sistemas de TI convencionales (cliente-servidor) en los que existe una única autoridad que controla el sistema y que es la única responsable de todas las operaciones en el sistema (Korth, Silberschatz, Sudarshan, y Pérez, 1987). Todos los usuarios de un sistema central dependen de sólo una fuente de servicio, entre los principales proveedores de servicios en línea se encuentran: eBay, Google, Amazon, App Store de Apple y la mayoría de otros proveedores, usan este modelo común de prestación de servicios.
Una red neuronal es un sistema que se adapta a las exigencias del entorno cambiando técnicas que procesan la información de manera paralela (Kung, 1993), una red neuronal está en posibilidades de realizar simultáneamente varios procesos y mostrar un adecuado comportamiento, por tanto, una red neuronal conforma un modelo computacional que, por sus componentes, potencializan la interconexión y facilitan la adaptación (Hassoun, 1995). Las redes neuronales artificiales imitan el comportamiento de los entes biológicos de manera artificial con modelos matemáticos, tal es el caso del cerebro humano (Rong y Xiaoning, 1998). En todo el funcionamiento y organización de la red, logra que en el proceso de información se haga uso del principio semejante a la estructura de las redes neuronales del cerebro humano (Lin et al.,1996), por lo que, el potencial de su utilización y aplicación se convierte indispensable para la investigación académica, la industria y en múltiples aplicaciones para las actividades humanas (Agrawal, et al., 2015; Dattakumar y Sharma. 2016; Dong, et al., 2013; W. Gu et al., 2016; Hao et al., 2016; Hordri et al.,2016; Larochelle, et al., 2009; Magni et al., 2016; Pizzi et al.,1990; Som, et al., 1987).
Los modelos de las redes neuronales se han dado en gran medida, debido a las necesidades de la sociedad, y por tal motivo los avances tecnológicos son la solución para algunos de ellos, los planteamientos matemáticos más conocidos en materia de redes neuronales se resumen en la Tabla 3.
Tabla 3
Modelos de redes neuronales
Nombre |
Aplicaciones |
Observaciones |
Perceptron |
Reconocimiento de caracteres impresos |
Considerada como la red más antigua y no puede reconocer caracteres complejos |
Self-Organi-zing-Map(SOM) |
Reconocimiento de patrones, codificación de datos, optimización. |
Realiza mapas de características comunes de los datos aprendidos, pero ocupa mucho entrenamiento y recursos computacionales. |
Máquinas de Boltzman |
Optimizar reconocimiento de patrones (imágenes, sonidos radares, etc.), |
Su capacidad de reproducción es óptima de patrones. Sin embargo, ocupa tiempos muy largos para su aprendizaje. |
Back Propagation |
Síntesis de voz desde texto, control de robots, predicción, reconocimiento de patrones. |
Es la red neuronal más popular, numerosas aplicaciones con éxito, facilidad de aprendizaje, necesita mucho tiempo para el aprendizaje y múltiples ejemplos. |
Teoría de resonancia adaptativa (ART) |
Reconocimiento de patrones (radar, sonar, etc.) |
Sofisticada, poco utilizada, sensible a la translación, distorsión y escala. |
Hopfield |
Reconstrucción de patrones y optimización. |
Puede implementarse en VLSI, fácil de conceptualizar, capacidad y estabilidad. |
La inteligencia artificial es utilizada en diferentes áreas del conocimiento (Carreño, et al., 2017; Huang, 2015; Yu, et al., 2005; Yu, y Li, 2010), esencialmente para abordar problemas que no son posibles resolver con métodos tradicionales o de manera artesanal o de ser así serian tareas repetitivas, cansadas e incluso imposibles de realizar por la gran cantidad de datos que se procesan. El reconocimiento de imágenes es un nicho de investigación utilizando la inteligencia artificial y las redes neuronales ya que permite identificar objetos mediante acuerdos de entrenamiento a la red con datos e imágenes, por lo que una red neuronal será capaz de identificar los atributos principales de un objeto.
El procesamiento de las imágenes digitales (Abdulin y Komogortsev, 2015; Dahiphale, Sathyanarayana y Mukhedkar, 2015; Goyal, 2015; Zhang, Liu y Tang, 2015) es importante para identificar patrones en objetos que permite garantizar a una red neuronal artificial su funcionamiento y verificar posibles inconsistencias, para así solucionar las desviaciones con técnicas que permitan mejorar la imagen original. El procesamiento implica ejecutar pasos como: a) obtención de imágenes comúnmente en formatos RGB; b) pre procesamiento, implica la reducción de ruido, contraste y suavizado, así como operaciones aritméticas con la finalidad de obtener características de una imagen en particular; c) segmentación, identificar los objetos presentes en la imagen, separándolas por regiones con técnicas de segmentación (las principales técnicas se muestran en la Tabla 4); representación y descripción, representada principalmente por una matriz binaria, por árboles binarios o cuaternarios, o por matriz de enteros.
Tabla 4
Técnicas de segmentación
Técnica |
Observaciones |
Segmentación por histograma |
Asume que existe un solo objeto con fondo uniforme, el histograma mostraría dos picos separados por un valle, representando la separación entre dos regiones. Comúnmente la segmentación por histogramas presenta inconvenientes como: identificar las variaciones en el histograma cuando el valle no es muy notorio y cuando las regiones varían suavemente su nivel, y se aplica solo cuando existen pocas regiones. |
Segmentación por crecimiento de regiones |
Consiste en seleccionar puntos iniciales en las imágenes (pixeles), y a partir de estos crecer paulatinamente por los pixeles similares hasta cierto límite. |
Segmentación por división-agrupamiento |
Hace uso de agrupamiento de regiones por métodos basados en pirámide o en árboles cuaternarios, dividiéndola en cuatro regiones y evaluando si satisface la medida para determinar si se sigue dividiendo cada región en más partes. |
Semántica de dominio |
Busca encontrar y separar las regiones teniendo cierta información a priori (dimensiones de la región, forma de la región, posición de la región en la imagen, posición de la región respecto a otras regiones, etc.) que le permita enfocarse la región de interés. |
Detección de bordes (Sobel, Shen-Castan (ISEF), Laplace, Marr-Hildreth, Canny) |
buscan diferenciar el objeto de interés de la imagen de fondo, localizando los pixeles del borde. |
Se identificó que aproximadamente el 74% de los artículos filtrados para extraer información relevante con respecto a las nuevas tecnologías utilizan una arquitectura de sistemas centralizados como por ejemplo: el procesamiento de gran cantidad de datos, el internet de las cosas, las redes neuronales, el procesamiento de las imágenes, etc., con el fin de simplificar los diferentes problemas, y una proporción del 26%, está investigando sobre temas relacionados con las nuevas tecnologías como la cadena de bloques para solucionar los problemas de escalabilidad, seguridad y confiabilidad y un 6% son arquitecturas para la Reconfiguración. Se destaca el trabajo de Tracey y Sreenan (2013), debido a la gran cantidad de citas que ha tenido de entre los trabajos seleccionados. Los autores proponen un conjunto de requisitos para lograr un sistema de información generalizado que integra sensores y servicios asociados a través de una red inalámbrica. La arquitectura, que es de Simplificación, proporciona un conjunto de abstracciones para los diferentes tipos de sensores y servicios. Ha sido diseñada para su aplicación en un nodo de recursos limitados y para ser extensible para entornos de servidores. Los autores demostraron que la arquitectura permite un enfoque holístico de alto nivel para almacenar datos de sensores.
Por otro lado, se reconoce el trabajo de Cecchinel, et al. (2014), debido a que es el segundo trabajo con mayores citas. Los autores proponen una arquitectura de “Big Data” que permite almacenar datos de los sensores en la nube, teniendo como objetivo dotar a un campus con sensores instalados en los edificios para crear aplicaciones innovadoras, como una plataforma abierta, que apoya a los usuarios finales (profesores, estudiantes, personal administrativo). Ambas arquitecturas se muestran en la Figura 2 para contrastar de manera visual los componentes de la arquitectura propuesta.
Figura 2
a) arquitectura propuesta por Tracey y Sreenan
b) arquitectura propuesta por Cecchinel et al.
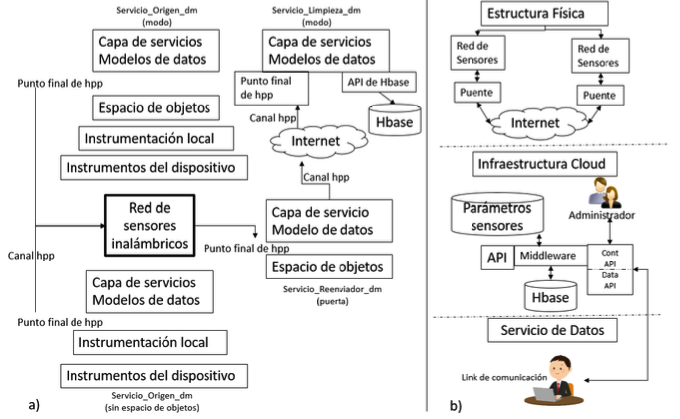
En la Figura 2 se puede observar que las arquitecturas propuestas presentan un conjunto de componentes, algunos componentes de la figura 2a son: red de sensores, modelo de datos, almacenamiento de datos en Hbase. Por otro lado, desde la figura 2b se observan: red de sensores, puente, base de datos, parámetros, entre otros. Cada trabajo revisado describe de manera distinta cada componente que integra la arquitectura diseñada, es por ello, que hemos clasificado el conjunto de componentes de la siguiente manera: a) Almacenamiento, es el componente que permite almacenar los datos provenientes desde los sensores u otras fuentes de datos; b) Procesamiento, es el componente que permite seleccionar, clasificar y dar formato a los datos de análisis; c) Análisis de datos, es el componente que define la forma cómo analizará los datos procesados; d) Sensores, describe el tipo y la forma de adquirir los datos desde los sensores; e) Interconexión, permite describir la forma de integrar la información, y f) Visualización, es la plataforma que muestra los resultado.
La arquitectura que destaca entre la literatura revisada es la filosofía del enfoque práctico del software subyacente de EOSIO, que tiene como finalidad extender la experiencia de la cadena de bloques en el alto rendimiento a gran escala para apoyar el negocio de los usuarios finales. La mayoría de los elementos han sido probados, la arquitectura propuesta por EOSIO (Figura 3) ensambla el propósito de construir sistemas descentralizados (Elrom, 2019). Para obtener más detalles técnicos, los interesados en el tema pueden consultar el denominado “Libro blando técnico de Larimer” (2017).
El diseño del software cambia del consenso más popular sobre el estado al consenso menos familiar sobre los eventos (Grigg, 2017), éste enfoque combina el patrón de abastecimiento de eventos (Flowler, 2005) con una cadena de bloques hecha de eventos en lugares de estado.
Figura 3
Arquitectura de EOSIO
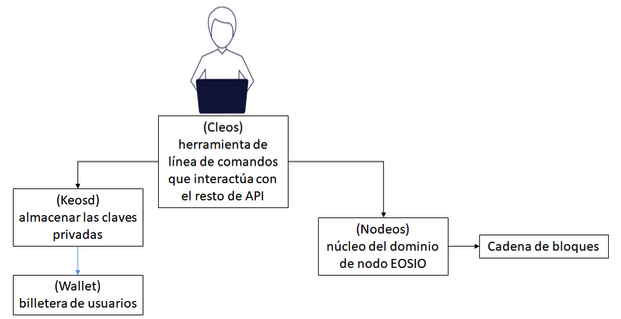
Una cadena de bloques basada en el software EOSIO supone que todos los que usan la cadena de bloques son miembros bajo una breve Constitución (Grigg, 2017b; Larimer, 2017b) y al acordar que todos los miembros forman una Comunidad sujeta a la Constitución, la Constitución establece algunas reglas básicas para el beneficio de la comunidad otorgando tres brazos de gobierno: arbitraje para resolver disputas, productores de bloques para elegir bloques y referéndums para la voz de la comunidad. Dispuestos en un triángulo de gobernanza entrelazado, estos tres brazos se apoyan y se compensan entre sí. Los referéndums son utilizados por la comunidad para votar en los productores y árbitros, así como los cambios en el código y la Constitución. Los árbitros pueden emitir fallos legalmente vinculantes para resolver disputas, y también para cambios extraordinarios como horquillas. Los productores de bloques tienen libertad técnica para censurar las transacciones malas o introducir las reparadoras, pero son conscientes de la reacción de la comunidad.
4.7. ¿Cuáles son las herramientas más utilizadas en el procesamiento de gran cantidad de datos?
Existe gran variedad de tecnologías reportadas en la literatura, sin embargo, se realizó un compendio de las tecnologías más citadas por los autores (Tabla 5).
Tabla 5
Herramientas más citadas para el procesamiento de datos
No. |
Tipo de herramienta tecnológica |
1 |
Hadoop |
2 |
Hbase |
3 |
MapReduce |
4 |
Mahout |
5 |
MongoDB |
6 |
Cluster |
7 |
MySql |
8 |
ArcGIS |
9 |
Cloud |
10 |
RFID |
11 |
Cosmos |
12 |
GPS |
13 |
Spark |
14 |
VoltDB |
15 |
CludView |
16 |
M2M |
17 |
Exalead |
18 |
Jaspersoft |
19 |
Cloudera |
20 |
Pentaho |
21 |
Eclipse |
Los trabajos revisados no indican las características especiales que obedecen a la selección de la herramienta utilizada. Sin embargo, los tipos de herramientas tecnológicas mencionadas en la tabla anterior fueron clasificadas en orden descendente, siendo Hadoop la más citada y Eclipse la menos mencionada.
La revisión de la literatura sistematizada reveló que existe gran variedad de investigaciones dirigidas a las tecnologías de carácter centralizado y existen, en menor proporción investigaciones de carácter descentralizado, abordando la inteligencia artificial como medio de solución a las problemáticas presentadas en el entorno industrial, académico y social. Sin embargo, se destaca el descubrimiento de aplicaciones utilizando las cadenas de bloques por sus capacidades integrando cada vez más investigaciones con esta novedosa tecnología, las diversas arquitecturas encontradas en los documentos son la muestra de los avances tecnológicos que se tienen para la resolución de problemas, se identificó que las investigaciones consideradas por cada uno de los autores se centran en la importancia del tratamiento y procesamiento de datos como una solución eficiente y efectiva a cada uno de los casos presentados.
Finalmente, consideramos que por el crecimiento que están teniendo las nuevas arquitecturas basadas en cadena de bloques para la próxima década tomará especial importancia, uso y aplicaciones a un sector de la población más amplio en temas que requieren tener información encriptada, segura y protegida. Otros temas de interés pueden ser la investigación de desarrollos de sistemas descentralizados, ingeniería de requerimientos, validación de datos y desarrollo dirigido por modelos.
Abdulin, E. y Komogortsev, O. (2015). User eye fatigue detection via eye movement behavior. In Proceedings of the 33rd annual ACM conference extended abstracts on human factors in computing systems 1265-1270
Agrawal, P., Madaan, V. y Kumar, V. (2015). Fuzzy rule-based medical expert system to identify the disorders of eyes, ENT and liver. International Journal of Advanced Intelligence Paradigms. 7. 352-367. 10.1504/IJAIP.2015.073714.
Bayer, D, Haber S.y Stornetta, W.S (1993) Improving the e±ciency and reliability of digitaltime-stamping, In Sequences II: Methods in Communication, Security and Computer Science, 329–334.
Berners-Lee, T., Hendler, J. y Lassila, O. (2001) “New form of web content that is meaningful to computers will unleash a revolution of new possibilities. Scientific American.
Canales, R. y Nanda, R. (2012). A darker side to decentralized banks: Market power and credit rationing in SME lending. Journal of Financial Economics, 105(2), 353–366. doi:10.1016/j.jfineco.2012.03.006
Carreño, R., et al. (2017) Comparative analysis on nonlinear models for ron gasoline blending using neural networks, Fractals 25(6) 1–8.
Cecchinel, C., Jimenez, M., Mosser, S. y Riveill, M. (2014) "An architecture to support the collection of big data in the internet of things," IEEE World Congress on Services, 442—449.
Dahiphale, V. E., Sathyanarayana, R. y Mukhedkar, M. M. (2015) Computer vision system for driver fatigue detection. Computer, IJARECE 4(9):2331–2334
Dattakumar, A. y Sharma, R.S. (2016). Smart cities and knowledge societies: Correlation, causation or distinct IEEE International Conference on Management of Innovation and Technology (ICMIT), 193–197.
Dattakumar, D. y Sharma, R.S. (2016) Smart cities and knowledge societies: Correlation, causation or distinct?2016 IEEE International Conference on Management of Innovation and Technology (ICMIT), 193–197.
Dong, H., et al. (2013). The Design and Implementation of an Intelligent Apparel Recommend Expert System. Mathematical Problems in Engineering. 10.1155/2013/343171.
Elrom, E. (2019). EOS. IO Wallets and Smart Contracts. In The Blockchain Developer, Apress, Berkeley, CA. 213-256
Fowler, M. (2005) “Event Sourcing”, 2005 https://martinfowler.com/eaaDev/EventSourcing.html
Goyal, R. (2015) Fatigue Detection Using Artificial Intelligence and Computer Vision Algorithms. 2015 AAAS Annual Meeting (12–16 February 2015)
Grigg, I (2017b) blog post “A Principled Approach to Blockchain Governance”
Grigg, I. (2017) blog post “The Message is the Medium,”
Gu, W., et al. (2016). Expert system for ice hockey game prediction: Data mining with humanjudgment, International Journal of Information Technology & Decision Making 15(4) 763–789.
Gwet, K. (2002) "Inter-rater reliability: dependency on trait prevalence and marginal homogeneity," Statistical Methods for Inter-Rater Reliability Assessment Series, 2, 1-9.
Hao, F., et al. (2016). Deep Learning, International Journal of Semantic Computing, 10 (3)
Hassoun, M. H. (1995). Fundamentals of artificial neural networks. MIT press.
Hordri, N.F., et al. (2016). Deep Learning and Its Applications: A Review, Postgraduate Annual Research on Informatics Seminar
https://github.com/EOSIO/Documentation/blob/master/TechnicalWhitePaper.md
Huang, G. B. (2015) What are extreme learning machines? Filling the gap between Frank Rosenblatt's dream and John von Neumann's puzzle, Cognitive Computation 7(3) 263–278.
Jin, X., Wah, B., Cheng, X. y Wang, Y. (2015) "Significance and challenges of big data research," Big Data Research, vol. 2, pp. 59--64
Kitchenham, B. y Charters, S. (2007) "Guidelines for performing systematic literature reviews in software engineering," Thechnical Report EBSE ́07.
Korth, H. F., Silberschatz, A., Sudarshan, S. y Pérez, F. S. (1987). Fundamentos de bases de datos. McGraw-Hill.
Krüger, K. (2006). El concepto de sociedad del conocimiento. Revista Bibliográfica de Geografía y Ciencias Sociales, XI, 683. Disponible en: http://www.ub.edu/geocrit/b3w- 683.htm
Kung, S. Y. (1993). Digital neural networks. Prentice-Hall, Inc.
Larimer, D. (2017) “EOS.IO Technical White Paper” block.one
Larimer, D. (2017b) blog post “What could a blockchain Constitution look like?”
Larochelle, H, Bengio, Y, Louradour, J. y Lamblin, P. (2009). Exploring strategies for training deep neural networks, Journal of Machine Learning Research, (10), 1–40.
Lin, C. T., Lee, C. G., Lin, C. T. y Lin, C. T. (1996). Neural fuzzy systems: a neuro-fuzzy synergism to intelligent systems (Vol. 205). Upper Saddle River NJ: Prentice hall PTR.
Magni, C. A., et al. (2016). An alternative approach to firms evaluation: Expert systems and fuzzy logic, International Journal of Information Technology & Decision Making 05(1) 195–225.
Montero, L. y Gewerc, A. (2018) La profesión docente en la sociedad del conocimiento. Una mirada a través de la revisión de investigaciones de los últimos 10 años The teaching profession in the knowledge society. A look through the research review of the last 10 years. RED. Revista de Educación a Distancia. 56(3) 1-22 DOI: http://dx.doi.org/10.6018/red/56/3
Nakamoto, S. (1998) Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 20 January 2019).
Petersen, K., Feldt, R., Mujtaba, S. y Mattsson, M. (2008) "Systematic mapping studies in software engineering," EASE'08 Proceedings of the 12th international conference on Evaluation and Assessment in Software Engineering. British Computer Society Swinton., 68-77.
Pizzi, N. J., et al. (1990). Expert system approach to assessments of bleeding predispositions in tonsillectomy/adenoidectomy patients, Advances in Artificial Intelligence 27 67–83.
Rong, C. G. y Xiaoning, D. (1998). From chaos to order: methodologies, perspectives and applications (Vol. 24). World Scientific.
Sillaber, C. y Waltl, B. (2017). Life cycle of smart contracts in blockchain ecosystems. Datenschutz und Datensicherheit-DuD, 41(8), 497-500.
Som, P, Chitturi, R., y Babu, G. (1987). Expert Systems Application In Manufacturing. Proceedings of SPIE - The International Society for Optical Engineering. 786. 474-479. 10.1117/12.940659.
Szabo, N. (1997) The idea of smart contracts. Nick Szabo’s Papers and Concise Tutorials. http://www.fon.hum.uva.nl/rob/Courses/InformationInSpeech/CDROM/Literature/LOTwinterschool2006/szabo.best.vwh.net/smart_contracts_idea.html
Tracey, D. y Sreenan, C. (2013) "A holistic architecture for the internet of things, sensing services and big data," Cluster, Cloud and Grid Computing (CCGrid),13th IEEE/ACM International Symposium, 546—553.
Valdés, V. y Gutiérrez-Esteban, P. (2018). Las Urgencias Pedagógicas en la sociedad del aprendizaje y el conocimiento. Un estudio para la reflexión sobre la calidad en el nuevo modelo educativo. Multidisciplinary Journal of Educational Research, (8), 1-28. doi:10.17583/remie.2018.3199 http://dx.doi.org/10.17583/remie.2018.3199
Weingart, P. (2011) The moment of truth for science: The consequences of the knowledge society for society and science, Beyond the Knowledge Trap, Singapore, 155–164.
Yu, W., et al. (2005) Neural networks for the optimization of crude oil blending, International Journal of Neural Systems 15(5) 377–389.
Yu, W. y Li, X. (2010) Automated nonlinear system modeling with multiple fuzzy neural networks and kernel smoothing, International Journal of Neural Systems 20(5) 429–435.
Zhang, L., Liu, F. y Tang, J. (2015) Real-time system for driver fatigue detection by RGB-D camera. ACM Trans Intell Syst Technol (TIST) 6(2): 22:1–22:17
1. Estudiante de doctorado. Sección de Estudios de Posgrado ESIME-Zacatenco del IPN, Maestro en Ciencias en Energía Solar. Email: adan.acosta.b@gmail.com
2. Profesor-Investigador, Universidad del Istmo, Maestra en Ciencias en Administración egresada IPN. Email: verodemygut@gmail.com. https://orcid.org/0000-0001-6024-47609
3. Profesor-Investigador. Universidad del Istmo, Doctor en Ingeniería de Sistemas del I.P.N. Email: ricardo.carreno.a@hotmail.com
4. Profesor-Investigador, Sección de Estudios de Posgrado ESIME-Zacatenco del IPN, Doctor en Ciencias en Ingeniería Mecánica del IPN. Email: mpatino2002@ipn.mx
5. Coordinador de Programa de maestría, especialidad y doctorado en Ingeniería de Sistemas, Profesor-Investigador, Sección de Estudios de Posgrado ESIME-Zacatenco del IPN, Doctor en Ciencias Administrativas y Doctor en Ciencias en Ingeniería Mecánica. Email: jpatinoo@ipn.mx
6. Profesor-Investigador, Sección de Estudios de Posgrado ESIME-Zacatenco del IPN, Doctor en Ciencias en Ingeniería por el IPN. Email: mamartinezc@ipn.mx
[Índice]
revistaespacios.com

Esta obra está bajo una licencia de Creative Commons
Reconocimiento-NoComercial 4.0 Internacional